728x90
반응형
나의 정리
- FC layer에 input size를 맞춰주기 위해 warp을 통해 강제적으로 맞춰주며 데이터 변형, 손실이 생겼는데 ROI pooling으로 input size에 무관하게 input으로 사용할 수 있게 되었다.
- backpropagation이 가능해져 모든 네트워크의 가중치가 업데이트될 수 있다.
- R-CNN은 bbox regressor, linear SVM을 각자 학습하는 multi-stage였지만 Fast R-CNN은 multi-task loss의 사용으로 single stage, end-to-end가 가능해졌다.
- 또한 fast R-CNN에서는 SVM 말고 softmax를 사용한다.
- feature map을 계산한 뒤 그 위에 object proposal을 projection 해서 사용하기 때문에 각각의 ROI마다 CNN연산을 해야 하는 연산량을 감소시켰다.
- SVD를 통해 fc layer의 cost를 감소시켰다.
- 하지만 여전히 region proposal을 구할 땐 selective search 알고리즘을 이용해서 input으로 받는다.
Abstract
- training and testing 시간을 줄이고 정확도도 높인 Fast R-CNN에 대해서 알아보자
- VGG16 network에서 R-CNN보다 9배 빠르게 학습했고 test time은 213배 빠르다.
정확도 또한 더 높은 mAP를 달성했다.
Introduction
- detection이 classification 보다 해결하기 더 복잡한데 이는 object localization 때문인데 이는 두 가지 문제점을 야기한다.
- Object가 있을만한 위치들의 후보군인 proposal을 설정해야 한다.
- proposal들은 rough localization을 통해 추려내기 때문에 정확성을 위해 정제 과정이 필요하다.
- classify object proposal과 정제 과정을 동시에 하는 single-stage training algorithm을 발표한다.
R-CNN and SPPnet
- R-CNN의 단점 3가지
- Training이 multi-stage pipeline이다.
→ 한 번에 학습이 안된다.
CNN을 log loss를 이용해 fine tune 하고 feature vector를 얻은 뒤 SVM에 적용시킨다.
SVM은 fine tuning으로 학습이 되고 마지막 세 번째 training stage로 bounding box regressor가 학습이 된다. - Training이 시공간적 비용이 비싸다.
SVM과 bbox regressor 학습 시에 이미지마다 각각의 object proposal에 대해 feature를 추출하고 disk에 써 시간과 메모리가 많이 든다.
feature를 저장해 두고 다시 써야 하기 때문에 - object detection이 느리다 (test time)
Test time에서 각각의 object proposal에 대해 feature를 추출하므로 오래 걸린다.
- Training이 multi-stage pipeline이다.
- 각각의 object proposal에 대한 forward pass 시에 연산을 공유하지 않아서 느린데 이를 개선한 것이 SPPnet이다.
SPPnet(Spatial Pyramid Pooling network)에 대한 간단 설명
기존 R-CNN은 CNN에 입력 크기를 맞추기 위해 crop, warp을 진행했다.
이때 crop은 이미지 정보 손실이 있을 수 있고 warp은 이미지에 변형이 일어난다.
Conv layer는 고정된 사이즈가 필요치 않지만 FC layer가 고정된 입력 크기를 필요로 하기 때문에 입력 크기를 맞춰줘야 하는데 SPPnet은 FC layer 이전에 SPP layer를 추가해서 conv layer가 임의의 크기를 입력으로 취할 수 있게 한다.
spatial bin의 개수를 정한다. (4x4, 2x2, 1x1 → 21 bin, 4x4는 pooling 적용하여 생성되는 출력의 크기 이를 일자로 펴서 사용한다.)
따라서 원하는 bin의 개수를 정해 fc layer로 들어가는 입력의 크기를 정할 수 있다.
이미지에 한 번만 적용해 속도가 빠르다.
- SPPnet은 연산을 공유해서 속도를 개선하였다.
하지만 결국 R-CNN처럼 multi-stage pipeline을 사용한다는 단점이 있다. (학습을 3번 진행해야 한다.) - fine-tuning 알고리즘은 spatial pyramid pooling 이전의 convolution layer들에 대한 값을 update 할 수 없어 deep 해지면 좋은 결과를 낼 수 없다. (한계가 존재)
Contributions
- 새로운 학습 알고리즘으로 R-CNN과 SPPnet에 비해 속도와 정확도에 대해서 개선을 하였다.
fast R-CNN의 4가지 장점- R-CNN, SPPnet보다 높은 mAP
- 학습은 multi-task loss를 이용하여 single-stage로 이루어진다.
- 학습 시에 모든 network layer에 대한 update가 가능하다.
- feature caching을 위한 disk 저장소가 필요 없어졌다.
Fast R-CNN architecture and training
- Fast R-CNN의 방식
- input으로 이미지 전체와 object proposal set이 들어온다.
- 전체 이미지가 conv와 max pooling layer를 거쳐 conv feature map을 추출한다.
- ROI pooling layer에서 feature map으로부터 각각의 object proposal마다 고정 길이 feature vector를 추출한다.
- 각각 feature vector는 Fully-connected layers를 통과해 두 브랜치로 나뉜다.
- K개의 object class + background → K+1에 대한 softmax 확률이 나오는 곳
- K개의 object class 각각에 대한 4개의 실수가 나오는 곳 → bbox 위치와 regression을 위해 사용된다.
The RoI pooling layer
- Fast R-CNN에는 1개의 피라미드를 적용시킨 SPP로 구성되어 있고 고정된 크기의 feature vector를 만드는 과정이 있는데 이를 RoI pooling이라고 한다.

- 그림은 feature map에 h*w 크기의 검은색 box가 projection 된 region proposal이다.
- Fast R-CNN에서 먼저 입력 이미지를 CNN에 통과시켜 feature map을 추출하고 이전에 미리 Selective search로 만들어 놨던 region proposal을 feature map에 projection 시킨다.

- 미리 설정한 H*W의 크기로 만들어주기 위해 (h/H)*(w/W) 크기만큼 grid를 RoI 위에 만든다.
ex) 6x4 , 2x2 → 한 grid 당 3x2로 나눈다. - RoI를 grid 크기로 split 시킨 뒤 max pooling을 적용해 각 grid 칸마다 하나의 값을 추출한다.
이를 통하여 h*w를 고정된 H*W 크기의 feature vector로 변환한다.
Initializing from pre-trained networks
- 각각 5개의 max pooling layer, 5~13 개의 conv layer를 가지는 3개의 pre-trained 모델을 3가지 변형을 하여 사용하였다.
- 마지막 max pooling을 첫 FC layer와 H, W가 호환되도록 세팅된 RoI pooling layer로 변경하였다.
- 마지막 FC layer와 softmax를 이전에 말한 K+1 softmax, bbox regressor로 변경한다.
- 이미지 list와 RoI list 두 가지를 input으로 사용한다.
two-stage 방식!
Fine-tuning for detection
- Fast R-CNN의 장점은 모든 network에 대하여 backprop을 통해 update가 가능하다는 것이다.
이는 곧 end-to-end 학습이 가능하다는 말! - fast R-CNN의 RoI가 너무 커서 기존 SPPnet, RNN에 적용된 방법을 사용하는 것은 비효율 적이다.
따라서 다른 방법을 사용했다. - SGD의 mini-batch를 계층적으로 샘플링했다.
처음 N개의 이미지를 뽑고, 각각의 이미지에서 R/N개의 RoI를 뽑아냈다.
같은 이미지에서 뽑은 RoI들은 forward, backward 모두 연산과 메모리를 공유한다.
ex) N=2, R=128이면 이미지 하나당 64개의 RoI를 샘플링하여 훨씬 빠르게 학습이 가능하다. - 이러면 같은 이미지에서 나온 RoI끼리 연관이 있어 수렴 속도가 늦어질 것이라는 우려가 있었지만 실제론 발견되지 않았고 SGD iter가 적어 좋은 결과를 가져왔다.
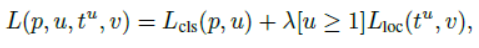

- Multi-task loss
- fast R-CNN은 두 가지 output layer로 나뉘게 된다.
- K+1 category에 대한 softmax를 이용한 이산 분포 확률
- bbox regression에 대한 출력
- 이 두 가지를 한 번에 학습하기 위해 multi-task loss를 사용한다.
u : class GT, v : bbox regression GT - [u≥1]은 u가 1 이상일 때 1의 값 그 외에는 0인 값을 가지는 function이다.
이를 이용하면 background는 u=0으로 라벨링 되어 loss 계산에서 무시할 수 있게 한다. - 이상치(Outliers)에 영향을 덜 받기 위해서 L1 Loss를 사용한다.
- lambda는 cls, loc 사이의 균형을 맞춰주는 hyperparameter이다.
- fast R-CNN은 두 가지 output layer로 나뉘게 된다.
- Mini-batch sampling
- IoU가 50% 이상의 RoI 25%를 사용, 50% 이하는 background로 취급
- Augmentation은 horizontal flip p=0.5 만 사용

- Back-propagation through RoI pooling layers
- xi : RoI pooling layer로 들어가는 i번째 activation input
yrj : r번째 RoI의 pooling layer의 j번째 output
[i = i*(r, j)] : yrj의 max pooling을 통한 argmax
- xi : RoI pooling layer로 들어가는 i번째 activation input

서로 다른 RoI에서 pooling을 진행했을 때 같은 x_23이 영향을 끼칠 수 있다.
이 말은 즉슨 하나의 xi가 여러 output yrj와 연관될 수 있다는 말이다.
따라서 backpropagation은 저런 값들의 합으로 생각을 하는 것이다.
- SGD hyper-parameter
- softmax classification, bbox regression의 FC layer는 각각 표준편차가 0.01, 0.001이며 평균이 0인 가우시안 분포로 초기화해준다.
- bias는 0으로 초기화
- per-layer의 가중치 LR은 1, bias는 2를 사용하고 global LR은 0.001 사용
- momentum 0.9, weight decay = 0.0005를 사용했다.
Scale invariance
- Scale invariance 하게 detection 하는 방법 2가지
- brute force: train, test시에 미리 정해놓은 size로 맞춰서 진행하는 것
- image pyramids: data augmentation의 형태로 여러 scale로 random 하게 진행한다. → multi-scale 접근법
Fast R-CNN detection
- 각각 test RoI r에 대해 클래스에 해당하는 p값과 bbox offset이 output으로 나온다.
- 이를 이용해 클래스와는 독립적으로 NMS를 진행한다.
Truncated SVD for faster detection


- Truncated SVD를 사용해 연산의 수가 줄어 속도가 엄청 빨라졌다.
- FC layer의 weight matrix W가 u*v였다면 uv만큼 연산을 해야 했다.
truncated SVD를 사용하면 t(u+v) 번만 하면 돼서 t가 u, v보다 작을 때 아주 큰 효과를 볼 수 있다.

- 하나의 FC의 weight matrix가 W였다면 이걸 위 형광펜 부분처럼 두 개의 FC로 나눈다.
첫 번째 layer에선 bias 없이 sigmat*Vt를 weight matrix로 가진다.
이후 activation function 없이 두 번째 layer에선 원래 W가 가지고 있던 bias를 가지며 U를 weight matrix로 가져서 두 FC를 거치게 되면 결국 최종 식과 같아진다.
Main results
- VOC07, 2010, 2012에서 Sota mAP 경신
- 빠른 train, test 속도
- VGG16의 conv layer를 fine-tuning시 mAP 상승
experimental setup
- 3가지 pre-trained 모델 사용
- Caffenet (small)
- VGG_CNN_M_1024 (Medium)
- VGG16 (Large)
- single-scale로 train, test 진행
Training and testing time
- Truncated SVD를 사용해 훨씬 빨라졌다.
- feature caching을 하지 않아 별도 저장공간이 필요 없다.
Which layers to fine-tune?
- FC layer만 fine tuning 하면 오히려 SPPnet(less deep network)에선 성능이 더 좋다.
- RCNN에서는 FC만 fine tuning 하는 게 좋지 않다.
- VGG16은 9번째 이전의 conv layer는 freeze 하고 그 이후 layer만 학습한다.
Design evaluation
Does multi-task training help?
- Yes
Scale invariance: to brute force or finesse?
- multi-scale 사용 시 더 성능이 좋지만 single-scale과 크게 나지 않고 메모리나 시간이 더 걸려 그냥 scale 쓴다.
Do we need more training data?
- data가 많으면 많을수록 좋다.
Do SVMs outperform softmax?
- VGG16에 대해 svm보다 softmax사용 시 0.1 더 높다
Are more proposals always better?
- proposal이 너무 많으면 성능이 저하된다.
728x90
반응형