나의 정리
- 간단하고 확장이 가능한 Object detection 방법을 소개했다.
- Selective search를 이용하여 region proposal을 구하고 해당 영역을 CNN에 통과시켜 feature vector를 추출한 뒤 FC layer를 거친 뒤 linear SVM을 거쳐 classify해준다.
- bounding box regression을 통하여 bounding box의 위치에 대한 평가를 하고 loss를 구해 GT값에 가깝게 만들어주는 d에 대해 학습하여 정확한 위치로 만들어 준다.
- data가 부족할 때 supervised pre-training을 사용하고 특정 domain에 대해서 fine tuning을 진행한다.
- bbox regressor, linear SVM 결국 두 개를 따로 학습해야 돼서 multi-stage이라 학습이 오래 걸린다.
- end-to-end가 아니고 real-time detect가 불가능하다.
Abstract
- mAP를 30% 이상 향상한 R-CNN 모델에 대해서 소개한다.
- 두 가지 insight
- Localize와 segment를 위한 bottom-up 방식의 region proposal을 CNN에 적용했다.
- data가 부족할 때 supervised pre-training을 사용하고 특정 domain에서 fine tuning을 진행한다.
- R-CNN : Region with CNN features
- sliding window와 CNN을 사용한 overfeat보다 성능이 좋다고 주장

Introduction
- 지금까지 주로 SIFT, HOG를 이용하여서 image recognition를 하였다.
하지만 이후 SGD기반의 CNN이 나오면서 더 좋은 성능을 내었다. - 두 가지 문제점이 있었다.
- Localizing objects with a deep network
- training a high-capacity model with only a small quantity of annotated detection data
capacity 란?
model의 parameter의 개수를 의미한다. high면 parameter가 많다는 의미
- (1) 해결 방법
- regression 문제로 localizing을 진행하는 방법
→ 실용성이 부족하다. - sliding-window detector 설계
→ network에서 large receptive field을 가져 잘 사용하지 않는다. - Recognition using regions
→ 이 방법을 논문에서는 추천한다.- 2000개의 독립적인 region proposal을 input image에서 추출한다.
- 각각의 proposal에서 정해진 길이의 feature vector를 CNN을 통해 추출한다.
- 각 카테고리마다 다른 linear SVM으로 region을 classify 한다.
이때, image warping을 이용해서 CNN의 input을 일정하게 고정시켜서 넣는다.
- regression 문제로 localizing을 진행하는 방법
- (2) 해결 방법
- unsupervised pre-training을 사용해 나중에 fine-tuning을 진행한다.
AlextNet으로 pre-training 된 모델을 사용할 수 있다.
- unsupervised pre-training을 사용해 나중에 fine-tuning을 진행한다.
Object detection with R-CNN
- 3가지 모듈 사용
- category-independent 한 region proposal을 생성하는 모듈
- 정해진 길이의 feature vector를 추출하는 large CNN
- 각 class마다 다른 linear SVM
Module design
Region proposals
- 여러 방식 중 Selective search로 region proposal 진행
Selective search란?
1. 색상, 질감, 영역 크기 등을 이용해 non-object-based segmentation을 수행
→ 이 작업을 통해 small segmented areas들을 얻는다.
2. Bottom-up 방식으로 small segmented areas들을 합쳐 더 큰 segmented area들을 만든다.
2번 작업을 반복해 최종적으로 2000개의 region proposal을 생성한다. (R-CNN에서)
- Feature extraction
- 여기선 ResNet을 이용해 4096-feature vector를 추출해 낸다.
- input은 227x227 RGB mean-subtracted 해주어 사용한다.
- input size를 맞추기 위해서 warping을 이용해 변환한다.
경계에 bbox가 있어서 그것이 들어가면 안 되므로 약간 확대시키고 p = 16 padding을 진행한다. - Appendix A

Test-time detection
Selective search로 test image에서 2000개의 region proposal을 추출한다.
추출한 region에서 각각 CNN을 통해서 추출한 feature vector를 SVM을 이용해 score를 내준다.
그 이후 greedy non-maximum suppression을 이용해 IOU가 threshold를 넘는지 확인한다.
greedy non-maximum suppression이란?
비 최대 억제는 object detector가 예측한 bounding box 중에서 정확한 bounding box를 선택하도록 하는 기법이다.
작동 단계
1. 하나의 클래스에 대한 bounding box 목록에서 가장 높은 점수를 갖고 있는 bounding box를 선택하고 목록에서 제거하고 final box에 추가한다.
2. 선택된 bbox를 bbox목록에 있는 다른 모든 bbox와 IoU를 계산하여 비교한다. IoU가 threshold보다 높으면 bbox 목록에서 제거한다.
3. bbox 목록에 남아있는 bbox에서 가장 높은 점수를 선택하고 목록에서 제거 후 final box에 추가한다.
4. 다시 선택된 bbox를 목록에 있는 box들과 IoU를 비교하고 threshold 보다 크면 목록에서 제거한다.
5. bbox목록에 아무것도 남아있지 않을 때까지 반복
6. 모든 클래스에 대해 반복
- Run-time analysis
- R-CNN이 효율적인 두 가지 이유
- 모든 category에서 CNN의 parameter를 공유한다.
- CNN으로 계산된 feature vector는 low-dimension이다. (다른 방법들에 비해서)
- dot product가 feature, SVM, NMS 사이에서만 존재해 계산량이 적어 빠른 추론이 가능하다.
- 따라서 R-CNN으로 수천 개의 class를 hashing 없이 계산해 낼 수 있다.
- R-CNN이 효율적인 두 가지 이유
Training
- Supervised pre-training
- large dataset에서 학습된 pre-training CNN model을 사용하였다.
- Domain-specific fine-tuning
- CNN을 detection과 새로운 domain에 적용하기 위해 SGD를 이용하여 CNN parameter를 warp 된 region proposal을 이용해서 학습을 진행한다.
- CNN의 1000개의 classification layer를 N+1 way classification으로 변경한다. 다른 구조는 변경하지 않는다. (N은 object class 개수, 여기에 배경을 더하기 위해 +1 해준다.)
- IOU 0.5 이상이면 positive, 그 이하면 negative로 분류
- LR = 0.001 SGD를 이용하고 32개의 positive windows와 96개의 background windows 총 128 개의 batch size로 학습하였다.
- Object category classifiers
- SVM에서 만약 car의 일부분이 overlap 되어 있다면 label을 어떻게 할 것인가?
- 이 질문에 대한 대답은 IoU overlap threshold를 통해 해결한다.
threshold 값을 잘 정하는 것이 중요하다. - standard hard negative mining method를 통해 빠르게 수렴하는 방식을 채택하였다.
- 각 class마다 하나의 linear SVM을 최적화한다.
- Appendix B
- fine tuning을 할 때와 training SVM을 할 때의 positive, negative exmaples를 다르게 설정하는 이유는?
⇒ fine-tuning에서는 IoU가 0.5 이상이면 positive, 그 외 negative로 놓는 반면 SVM을 훈련시킬 땐 0.3 이상이면 positive, 그 외 negative일 때 성능이 더 잘 나왔기 때문에 이렇게 설정하였다. - 왜 fine-tuning 이후 SVM으로 train 하는가?
⇒ softmax 방식의 regression classifier는 성능이 떨어지기 때문에 SVM으로 훈련 classifier를 선택했다. - 기존 방식보다 더 좋은 mAP를 달성하였다.
- hard negative mining을 이용해서 학습함
- fine tuning을 할 때와 training SVM을 할 때의 positive, negative exmaples를 다르게 설정하는 이유는?
Visualization, ablation, and modes of error
Visualizing learned features
- 첫 번째 layer는 edge와 보색을 찾아 이해하기 쉽고 직관적으로 시각화가 가능하지만 다른 layer들은 어려워서 non-parametric 방법을 사용한다.
- 큰 region proposal에 대한 unite activation을 진행 → activation 결과가 높은 것부터 낮은 것까지 sort 한다. → Non-maximum suppression 진행 → region의 top score를 시각화한다.
- 이 과정을 통해 각 layer마다 어떻게 학습하는지 알 수 있다.
- 네트워크가 모양, 질감, 색, 물질의 속성과 같은 작은 특징들을 모아서 학습하는 것처럼 보인다.
Ablation studies
- Performance layer-by-layer
- 어떤 layer가 중요한지 이해하기 위해 CNN 마지막 layer 3개를 분석했다.
- fine tuning 없이 수행했을 때 fc6, fc7이 없을 때 성능이 더 좋았다.
- 이를 통하여 CNN은 convolutional layer가 중요한 것을 알 수 있었고, 이는 DPM의 pool 5 layer에서 sliding-window detector를 수행할 수 있게 했다.
- Performance layer-by-layer, with fine-tuning
- fine tuning을 이용하는 게 성능이 더 좋다.
- fine tuning이 pool 5 layer보다 fc6, fc7 layer를 더 개선 한 것을 보아 pool5 feature는 ImageNet에서 학습하고 도메인에 대한 fine tuning은 non-linear에 적용이 된다.
- Comparison to recent feature learning methods
- feature learning을 사용하여 학습을 진행하는 경우를 비교한다.
- standard HOG-based인 DPM을 사용하는데 이때 두 가지 방법으로 사용
DPM ST(sketch token), DPM HSC (histogram of sparse codes)
Network architectures
- 대부분의 결과들이 AlexNet구조를 사용해 구했지만 구조 선택이 R-CNN의 성능에 큰 영향을 미치는 것을 발견하였다.
- 따라서 VGG pretrained network weights를 사용해서 진행해보았다.
O-Net이 T-Net보다 mAP 58.5% → 66%로 좋았다. 하지만 계산량이 7배 많아졌다.
Bounding-box regression
- Localization error를 줄이기 위해 DPM의 bounding box regression을 진행한다.
bounding box regression 이란? (Appendix C) input: region proposal
selective search region proposal을 통해 찾아낸 2000개의 박스 위치는 상당히 부정확하다.
따라서 예측한 predicted box를 GT box로 교정해주는 regression이 필요하다.
P를 transformation 함수 d를 이용해서 변경해주는데 이 d를 얻어 P와 GT의 차이를 줄이는 것이 목표이다.
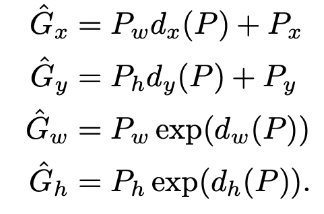
x, y는 점이기 때문에 이미지 크기와 상관없이 이동시켜주지만 w와 h는 이미지 크기에 비례해서 조정을 시켜준다.


d를 학습시키기 위해 Loss function을 세운다.
MSE loss function에 L2 normalization을 추가한 형태이다. pool 5 layer와 w를 곱하는 형태
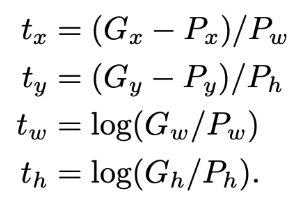
이때 t는 P를 G로 이동시키기 위해 필요한 이동량을 의미한다.
정리하면 CNN을 통과하여 추출된 벡터와 x, y, w, h를 조정하는 함수의 웨이트를 곱해 bbox를 조정해주는 선형 회귀를 학습시키는 것이다.
- Regularization은 중요하다.
- P를 아무거나 선택할 수 없기 때문에 GT box G의 IoU overlap을 최대화하는 것을 P로 선택한다. threshold 사용
Qualitative results
- 모든 detection의 precision이 0.5를 넘겼다.
The ILSVRC2013 detection dataset
Dataset overview
- train : 395,918
val : 20,121
test : 40,152 - train dataset의 경우 negative image들을 포함한 완전하지 않은 주석처리의 상태이기 때문에 hard negative mining이 불가.
따라서 val과 train dataset 중 positive images들을 사용하여 val1, val2로 나누고 class마다의 숫자 불균형을 맞추기 위해 a randomized local search 사용.
Region proposals
- Selective Search의 fast mode를 사용해 val1, val2,, test에 적용, 이미지의 폭을 500 pixel로 맞춤
Training data
- Negative exmaple을 전혀 사용하지 않은 상태로 CNN fine-tuning, SVM training, bounding-box regressor training을 수행
Validation and evaluation
Ablation study
- train 개수를 늘릴수록 fine-tuning을 할수록 bounding box regression을 수행할수록 mAP가 더 좋아진다.
Relationship to OverFeat
- Overfeat은 R-CNN보다 빠르다. warp을 하지 않고 overlapping window를 공유해 더 빠를 수 있다.
Semantic segmentation
- Region classification은 semantic segmentation을 위한 표준 기술이다.
- 3가지 방법
- full -R-CNN : 사각형 shape을 무시하고 waped windows에 CNN feature들을 바로 계산하는 방법
- fg R-CNN : region’s foreground mask가 덧씌워진 부분들만 CNN에 넣어 계산하는 것, 그 외의 부분은 배경의 평균값을 넣음으로써 후에 평균 값을 빼 0이 되게 한다.
- full + fg R-CNN : full과 fg 둘 다 사용하는 방법
- VOC 2011 test에서 다른 segmentation 방법들과 비교하였을 때 대체로 full + fg R-CNN 방법이 더 좋았다.
Conclusion
- 이 논문에서 간단하고 확장 가능한 object detection 알고리즘을 발표했다.
- high-capacity CNN을 localize와 segment를 위해서 bottom-up region proposal로 이용한다.
high-capacity CNN이란? 더 깊은 network로 복잡한 기능을 수행할 수 있는 CNN
- 라벨링 된 train data가 적어도 supervised pre-training/domain-specific fine tuning을 적용하여 성능 향상을 이뤄냈다. large image dataset으로 학습한 pre-training 사용
- 학습 시간이 매우 오래 걸리고 연산을 공유하거나 가중치 값을 update 하는 것이 불가능하다는 문제가 있다!
'Paper review > 2D Object detection' 카테고리의 다른 글
| [논문 리뷰] (RetinaNet) Focal Loss for Dense Object Detection (0) | 2022.07.01 |
|---|---|
| [논문 리뷰] SSD: Single Shot MultiBox Detector (0) | 2022.06.30 |
| [논문 리뷰](YOLO)You Only Look Once:Unified, Real-Time Object Detection (0) | 2022.06.28 |
| [논문 리뷰] Faster R-CNN: Towards Real-Time ObjectDetection with Region Proposal Networks (0) | 2022.06.24 |
| [논문 리뷰] Fast R-CNN (4) | 2022.06.24 |