728x90
반응형
나의 정리
- RetinaNet은 one-stage로 동작하고 end-to-end 학습이 가능하다.
- network design은 RPN의 anchor, SSD의 feature pyramid 방식을 사용하여 기존의 network와 거의 비슷하지만 class imbalance 문제를 focal loss를 사용하여 해결했다.
- Focal loss는 hard exmaple에 초점을 맞춰서 학습을 진행하는 방식이다.
- 그냥 focal loss 보다 alpha-balance를 사용한 focal loss가 더 성능이 좋았다.
Abstract
- One-stage detector는 YOLO, SSD 등이 있다.
속도는 빠르지만 정확도는 two-stage에 비해 낮다.
→ 논문에선 왜 그럴까에 대한 분석을 진행 - one-stage가 정확도가 낮은 이유 분석
- 학습을 할 때 극단적인 클래스 불균형이 낮은 정확도를 불러일으킨다.
클래스 불균형 → detect 할 물체 vs 배경 일 때 물체에 비해 배경의 수가 훨씬 더 많아 생기는 문제
(YOLO에서 한번 다룬적 있다. 대부분의 grid가 0으로 학습되는 문제였고 YOLO에선 가중치를 이용하여 해결했다.) - 여기 논문에서는 Cross Entropy Loss를 reshape을 통하여 해결한다.
⇒ Focal loss라고 이름을 붙였다.
- 학습을 할 때 극단적인 클래스 불균형이 낮은 정확도를 불러일으킨다.
- Focal Loss에 분류하기 쉬운 문제보다 분류하기 어려운 문제(object-foreground)에 더 많은 가중치를 적용함 으로써 Object 검출에 더욱 집중하여 학습을 진행한다.
foreground 란?
detect할 object!
- Inference 시간이 빠르고 two-stage detector의 정확도보다 높다.
Introduction
- R-CNN과 같은 two-stage detector 같은 경우
first stage : region proposal을 생성한다.
second stage : 해당 proposal의 class를 CNN을 이용하여 classification
이런 과정을 거치게 되는데 first stage에서 object가 존재할 확률이 높은 proposal을 생성하기 때문에 class imbalance 문제에 덜 민감하다.
또한 second stage에서 1:3 혹은 Online Hard Example Mining을 사용해 object와 background의 비율을 맞춰준다. - One-stage는 region proposal 과정을 거치지 않고 CNN의 결과인 feature map에서 localization을 진행한다.
- 이를 위해 anchor box를 사용하며 anchor box에 여러 scale, aspect ratio를 적용한다.
- RetinaNet에서는 학습 도중 class 불균형 문제를 해결하기 위해 새로운 loss function인 Focal loss를 제안하여 해결하였다.
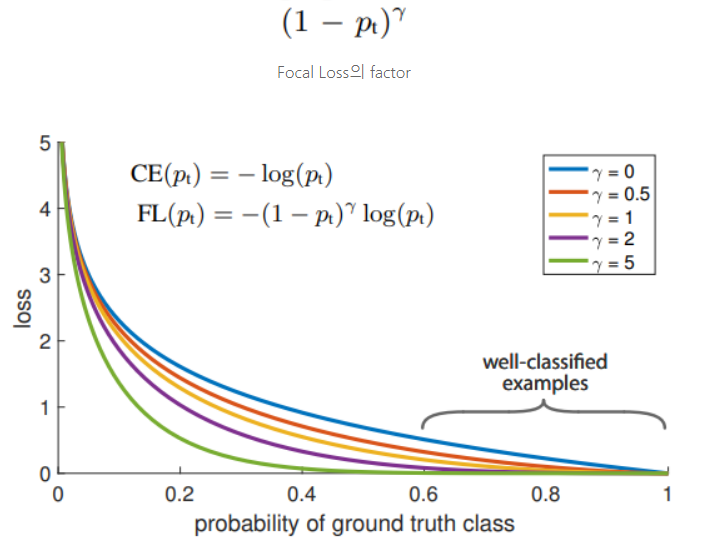
- Focal loss는 기존 Cross Entropy Loss에 factor를 적용한 것 학습 시에 자동적으로 쉬운 example를 down weight 하고 빠르게 어려운 example에 대해 집중할 수 있게 만들어 준다.
- Focal loss가 기존의 sampling heuristics, hard example mining보다 더 효과적이고 간단하다.
Related Work
Classic Obejct Detection
- sliding window 기반으로 동작했고 대표적인 모델로 HOG, DPM이 있다.
Two-stage Detectors
- first stage - region proposal, second stage - classification (object, background)로 two-stage
- R-CNN은 Selective search와 같은 알고리즘으로 region proposal을 사용
- Faster R-CNN은 RPN으로 region proposal을 GPU 환경에서 구해 더 빠르게 사용이 가능하였다.
One-stage Detectors
- OverFeat, YOLO, SSD 등이 있는데 속도는 빠르지만 two-stage에 비해 정확도가 떨어짐
- SSD : object localize에 여러 개의 feature map을 사용해 작은 물체의 detect도 가능하다.
- YOLO : 속도-정확도 간의 trade-off가 가능하다.
- RetinaNet은 RPN의 anchor, SSD의 feature pyramid를 사용하여 네트워크 디자인의 혁신보다는 loss를 사용하여 성능에 좋은 영향을 주었다.
Class Imbalance
- one-stage detector의 경우 class imbalance 문제에 직면한다.
class imbalance problem
→ detector들이 이미지 당 1~10만 개의 candidate locations을 생성하지만 그중 검출할 object를 포함한 location은 몇 개 없다.
object와 background의 imbalance 이것이 class imbalance 문제이다.
- class imbalance는 2가지 문제를 야기한다.
- 대부분의 locations은 학습에 쓸모가 없는 배경이기 때문에 학습이 비효율 적이다.
- 배경이 학습에 영향을 줘서, object를 검출하지 못하거나 배경으로 검출하는 오 검출을 야기한다.
- 이에 대한 공통적인 해결책으로 hard negative mining이 있다.
Focal loss는 sampling 하거나 기울기를 계산하지 않고 효율적으로 문제를 해결할 수 있다.
hard negative mining
→ 학습 도중 hard negative sample (배경인데 object라고 예측하기 쉬운 example들)을 sampling 하여 학습에 다시 사용
Robust Estimation : Loss function
- 기존에는 robust 한 loss function을 사용하였다.
Huber loss는 hard example(큰 error 값을 가지는 것)의 loss를 down-weight 함으로써 outlier의 민감도를 줄였다. - 이와는 반대로 focal loss는 easy example의 loss를 down-weight 함으로써 inliers의 민감도를 줄임으로써 class 불균형 문제를 해결하였다.
- Focal loss는 hard example의 학습에 초점을 맞춘다.
Focal Loss
- Focal loss는 one-stage object detector의 극단적인 class imbalance 문제를 해결하기 위해 design 된 loss function이다.
- binary classification에서 사용되는 cross entropy error를 변형한다.
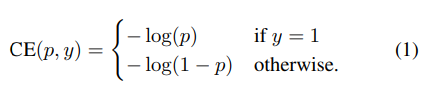
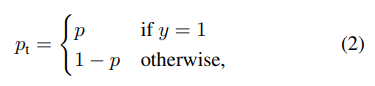
- P_t : 해당 class가 존재할 확률로 정의한다.
따라서 아래와 같이 간단하게 표기가 가능하다.
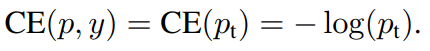
- Cross Entropy의 특징으로 P_t가 0.5보다 커도 loss값이 꽤 있는데 이런 특징 때문에 easy examples (P_t가 0.5보다 큰 examples)이 많이 있다면, 이러한 loss들이 쌓이고 쌓여서 물체를 검출하지 못하는 나쁜 방향으로 학습이 될 가능성이 있다.
Balanced Cross Entropy
- alpha-balanced CE loss : class 불균형을 해결하기 위해 일반적으로 CE에 weighting factor alpha를 적용한 것.
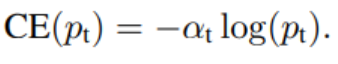
- 검출할 클래스 : alpha 0~1 사이 적용
배경 : 1-alpha 적용 - 이것은 Focal loss의 기반이 되는 수식이다.
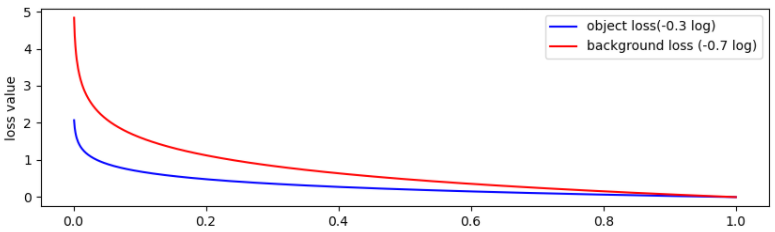
object에 대한 loss는 작게, background에 대한 loss는 크게 설정할 수 있다.
Focal Loss Definition
- alpha-balanced CE loss의 장점 : positive/negative example의 차별성을 표현 가능하다.
단점 : easy(P_t > 0.5)/hard example(P_t < 0.5)의 차별성이 표현 불가능하다.
- Focal loss는 easy example에 대한 가중치를 줄이고 hard negative example(배경인데 object라고 판단하기 쉬운 example)의 학습에 초점을 맞추도록 alpha-balanced CE loss를 수정한다.
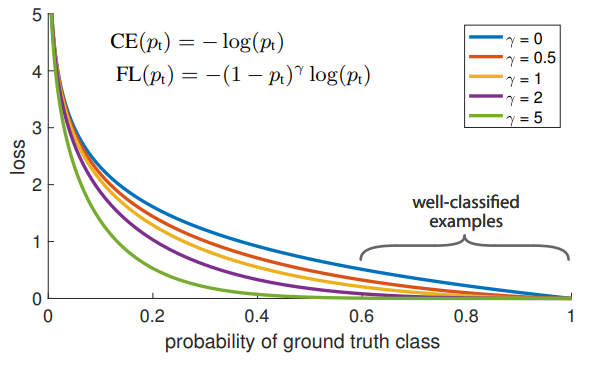
- CE에 modulating factor (1-p_t)^gamma를 추가한다. (gamma ≥ 0 , focusing parameter)
- Focal loss의 두 가지 특징
- P_t 값이 작을 때, modulating factor는 거의 1에 근접하며 loss 값이 커짐
P_t 값이 클 때 modulating factor는 0에 근접하며 well-classified examples(P_t>0.6)의 loss 값이 작아진다. - 감마 값이 커질수록 modulating factor의 영향이 커진다.
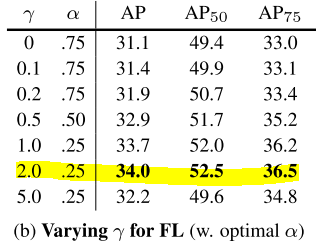
(gamma = 2가 가장 좋은 성능을 냈다고 한다.)
- P_t 값이 작을 때, modulating factor는 거의 1에 근접하며 loss 값이 커짐
- modulating factor는 easy example의 loss 값을 더욱더 작게 만든다.
alpha-balanced variant of the focal loss
- alpha-balanced를 적용한 focal loss의 형태 (이 형태가 그냥 focal loss보다 성능이 좋았다)
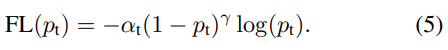
Class Imbalance and Model Initialization
- 기존의 classification model은 output이 1 or -1로 고정되었다.
- 여기선 object에 대한 모델이 추정한 확률 p에 대한 개념을 추가하였다.
p → prior라고 이름을 붙이고 π라고 표기 - prior를 적용한 CE와 focal loss 모두 학습 안정성을 향상한다.
RetinaNet Detector
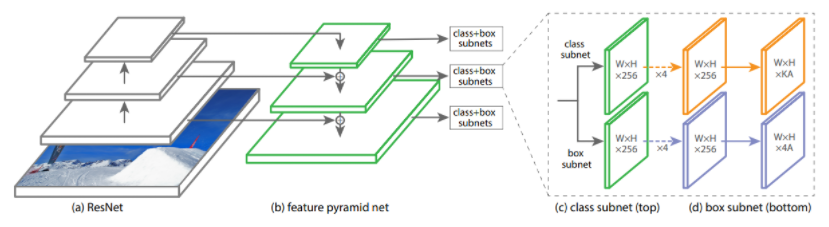
- FPN backbone과 두 개의 subnet(class & box regression)을 사용한다.
- feedforward로 ResNet을 사용
- ResNet 상단에서 FPN 백본을 사용하고, multi-scale convolutional feature pyramid를 생성 → anchor box 생성
- anchor box의 class를 예측하는 class subnet
- anchor box와 GT box를 비교하여 regression을 진행하는 box subnet
Feature Pyramid Network Backbone
- FPN은 하나의 이미지에 대해 multi-scale feature pyramid를 생성한다.
각 level의 pyramid는 다른 scale에서 object를 detect 하는 데 사용되고 이는 작은 크기부터 큰 크기의 object의 detect 능력을 향상한다. - ResNet의 상단에 FPN을 적용시킨다.
Anchors
- 3개의 aspect ratio를 지니는 anchor를 사용한다. (1:2, 1:1, 2:1)
- 각 pyramid level에서 anchor size 3개를 적용한다. (1, 1.26, 1.58)
- 각 level마다 9개의 anchor를 사용했고 scale의 범위는 32~813 pixel을 사용
- anchor box의 IoU의 threshold는 0.5를 사용, 0.4~0.5 사이의 IoU anchor box는 무시, 0~0.4는 background라고 정의
Classification Subnet
- 각 anchor box 내의 object가 존재할 확률을 predict 한다.
- FPN level에 작은 FCN을 붙인다. 3x3 conv layers, ReLU activations
Box Regression Subnet
- class subnet과 같이 작은 FCN을 붙인다.
- 각 앵커 박스의 offset 4개 (box_x_center, box_y_center, box_width, box_height)를 GT 박스와 유사하게 regression 한다.
- class-agnostic bounding box regressor를 사용하여 class 정보 없이 anchor box를 regression 한다.
- class와 box subnet은 개별적인 파라미터를 사용한다.
Inference and Training
Inference
- FPN level에서 box prediction 점수가 높은 1000개의 box만 result에 사용하고 최종 detection에 NMS를 적용해 속도 향상을 시킴
Focal Loss
- class sub의 output으로 Focal loss를 사용했다.
- gamma = 2, alpha = 0.25일 때 가장 좋은 결과가 나왔다.
Initialization
- FPN의 initialization은 FPN 논문과 같은 값으로 진행
- RetinaNet subnet에서 마지막 layer를 제외한 모든 conv layer는 bias=0, gaussian weight fill = 0.01로 초기화했다.
- classification subnet의 마지막 conv layer는 bias=-log((1-pi)/pi)로 초기화
Optimization
- SGD 사용
- LR = 0.01, 90000번 학습을 진행한다.
- 60000번 일때 LR 10 나누고, 80000번 일때 LR 10 나눈다.
- weight decay = 0.0001, momentum = 0.9
- class predict은 focal loss, box regression은 smooth L1 loss 사용
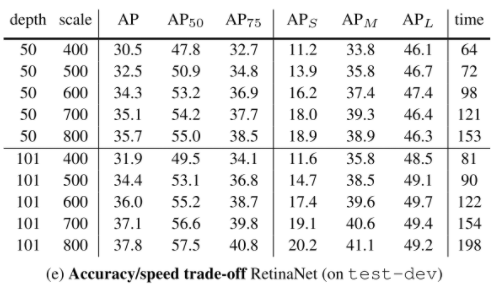
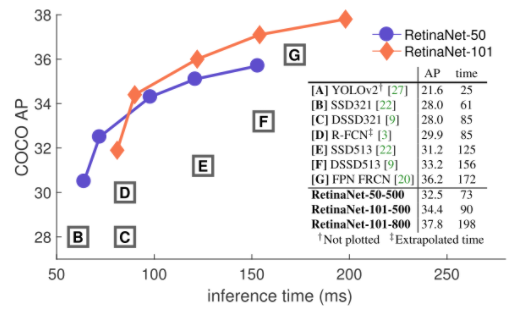
Experiments
728x90
반응형