나의 정리
- 논문이 지적한 문제점
기존의 monocular 3D detection의 경우 많은 논문들이 depth 정보를 만들어내 detection을 진행하는데 이 때 부정확한 depth 정보를 만들어 내기 때문에 LiDAR detector에 비해 낮은 성능을 내고 있다고 주장합니다. 하지만 이 논문은 부정확한 depth 정보가 성능 차이를 내는 것이 아니라고 주장합니다. - 해결 방안
부정확한 depth 정보가 아닌 3D object detection에 더 어울리는 representation은 point cloud이기 때문에 LiDAR detector보다 낮은 성능을 내는 것이라고 주장합니다. 따라서 이 논문은 image로 depth map을 생성한 뒤 estimated depth map을 통해 Pseudo-LiDAR, 즉 point cloud representation의 data를 생성하여 LiDAR detector를 이용해 3D object detection을 진행합니다.
2019년 CVPR에 발표된 Pseudo-LiDAR를 읽어보겠습니다.
Abstract
비교적 저렴한 sensor인 camera는 depth에 대한 정보의 부재로 인해서 3D object detection시에 낮은 정확도를 가집니다. 하지만 이 논문은 낮은 정확도의 원인을 camera의 depth 정보에 대한 부재가 아닌 data의 representation의 문제라고 주장합니다.
따라서 image로 depth map을 만든 뒤 depth map으로부터 Pseudo-LiDAR로 LiDAR 신호와 비슷하게 data를 생성하여 기존과 다른 representation으로 3D object detection을 진행합니다.
KITTI dataset에서 평가되었고 SOTA 성능을 냈습니다.
Introduction
기존의 연구들에서 3D object detection을 위해서 monocular depth estimation이나 stereo disparity estimation을 사용하는 경우가 있었습니다. 하지만 이러한 방법들은 LiDAR에 비해서 낮은 성능을 가지고 있습니다.
LiDAR-based model과의 성능 차이에 대한 분석 중 가장 많이 언급되는 이유로 image-based depth estimation의 경우엔 예측된 depth의 정확도가 낮아서 생기는 차이 때문이라는 이유가 있습니다.

하지만 위 그림을 보면 SOTA 성능의 stereo depth estimator의 경우엔 LiDAR data와 비교하여 보았을 때 매우 높은 퀄리티의 depth map을 생성하는 것을 볼 수 있습니다.
따라서 이 논문은 LiDAR와 iamge-based의 성능 차이는 depth 정확도의 차이가 아닌 image-based 방식이 3D object detection을 위해 사용되는 convolution system에 적합한 representation이 아니기 때문에 생기는 차이라고 설명합니다.
→ 즉 point cloud의 형식으로 data를 표현하는 것이 3D object detection에서 사용되는 convolution 구조에 더 적합한 표현 방식이므로 image와 depth map으로 진행하면 성능 차이가 나게 된다는 의미입니다.
point cloud나 BEV 상에서는 shape이나 size가 depth에 대해서 불변하지만 image의 경우엔 불변하지 않습니다. image 상에서는 물체가 멀어지면 size가 작아지고 shape도 달라지기 때문에 멀어지면 멀어질수록 detection이 어려워집니다.
따라서 two-step을 이용해서 위 문제를 해결합니다.
- stereo나 monocular image를 이용해서 depth map을 estimation하고 depth map으로 back projection 시켜 Pseudo-LiDAR point를 얻습니다.
- 얻은 Pseudo-LiDAR point로 LiDAR-based detector에 넣어서 3D bbox를 예측합니다.
Pseudo-LiDAR의 contribution을 정리하면 아래와 같습니다.
- 기존의 image-based detector와 LiDAR-based detector의 성능 차이는 depth estimation 성능 차이가 아닌 representation의 차이임을 밝혔습니다.
- KITTI dataset에서 SOTA 성능을 냈습니다.
Approach
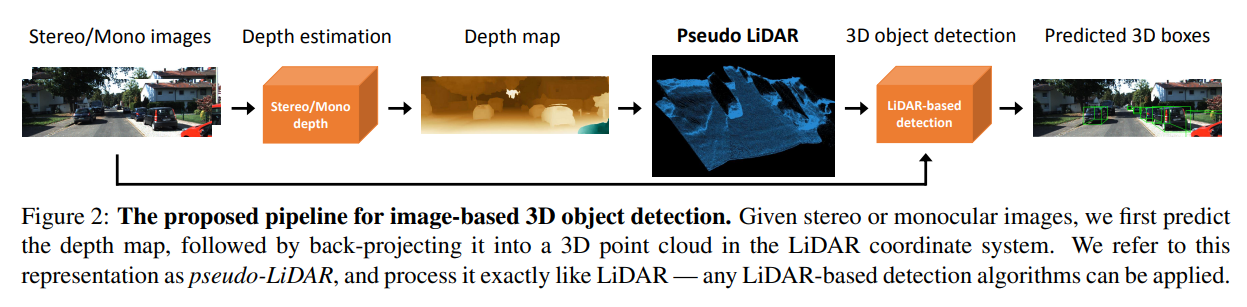
아래 절차를 거치는 approach를 제안합니다.
- image (stereo or mono)로 dense depth map을 생성합니다.
- depth map에서 point cloud로 back-projection하여 3D point cloud를 생성합니다. (Pseudo LiDAR 생성)
- 기존의 LiDAR-based model을 사용해 3D object detection을 진행합니다.
Depth estimation.
Pseudo-LiDAR는 monocular, stereo로 모두 실험하였습니다. 여기에 쓰이는 depth estimation에 대해서 간략히 설명하는 부분입니다.
Stereo disprity estimation은 input으로 수평한 baseline을 가지는 한 쌍의 $I_l, I_r$(left image, right image)를 받아서 input image와 같은 해상도의 disparity map을 만드는 과정입니다.
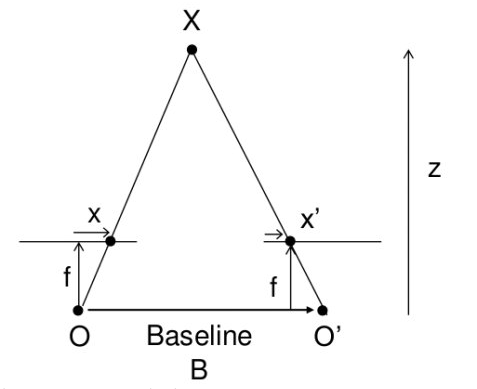
수평한 baseline을 가지는 한 쌍의 image라는 이해를 돕기 위한 사진입니다.
만들어진 disparity map으로 depth map을 만드는 수식은 아래와 같습니다.

u, v는 pixel coordinate이고 D는 depth map, Y는 disparity map, $f_U$는 horizontal focal length, b는 horizontal offset을 의미합니다.
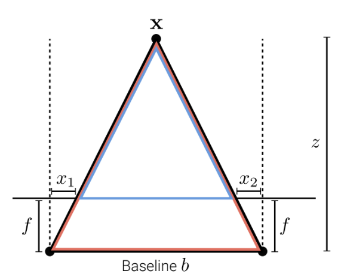
이 수식은 간단한 닮음 비로 설명이 되는데, 아래 그림과 같은 경우 disparity $d = x_1-x_2$로 정의되고 $\frac{z-f}{b-d} = \frac{z}{b}$라는 삼각형의 닮음 비로 $z=\frac{fb}{d}$라는 식이 도출되게 됩니다.
Pseudo-LiDAR generation.
Depth map을 back-projection 시키는 과정이고 수식은 아래와 같습니다.

$(c_U,c_V)$는 camera center의 pixel 위치 값을 의미하고 $f_U,f_V$는 각각 horizontal, vertical focal length, D는 depth map을 의미합니다.
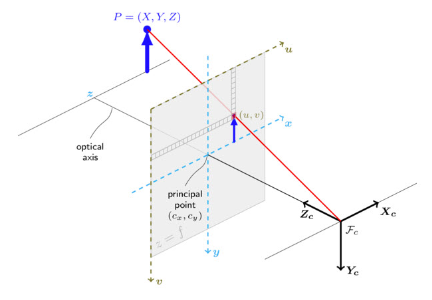
위의 수식들도 모두 삼각형의 닮음 비로 설명이 가능합니다.
먼저 depth 같은 경우 depth map에서 해당하는 pixel의 값이 곧 depth가 됩니다.
width의 경우에는 삼각형의 닮음 비의 식 $\frac{f_U}{u}=\frac{z}{x}$를 변환하면 $x=\frac{uz}{f_U}$가 됩니다. 여기서 image의 center를 맞춰주기 위해서 u에 $c_U$를 빼주면 위의 식이 완성됩니다.
image의 모든 pixel (u, v)를 위의 식을 통해서 3D point cloud (x, y, z)로 back projection 시킨 값들을 Pseudo-LiDAR라고 합니다.
LiDAR vs. pseudo-LiDAR.
Pseudo LiDAR를 생성한 뒤 실제 LiDAR point cloud와 비슷하게 만들어주기 위해서 post-processing을 거칩니다.
실제 LiDAR의 경우에는 일정 범위 내의 높이에만 존재합니다.
→ LiDAR 센서가 뿌리는 point cloud의 범위가 존재하기 때문입니다.
따라서 Pseudo-LiDAR도 높이의 일정 범위 내의 값들만 남기고 나머지 값들은 삭제를 해줍니다.
또한 LiDAR는 reflectance라는 정보를 가지고 있습니다.
→ reflectance는 LiDAR가 반사된 정도를 의미합니다.
하지만 Pseudo-LiDAR는 이러한 정보가 없기 때문에 모두 그냥 1.0으로 setting을 해주었다고 합니다.
→ 왜…? 학습에 영향을 많이 끼치지 않는 탓일까..
3D object detection
Pseudo-LiDAR를 input으로 사용하여 실제로 3D object detection을 할 모델을 소개합니다.
두 가지 모델에서 실험을 진행하였습니다.
- AVOD: RGB image와 LiDAR를 사용하는 model, high resolution feature를 fusion하고 이후 second stage에서 proposal들에 대한 feature 끼리 한번 더 fusion을 하는 방식
- Frustum PointNet: 2D object detection을 3D의 frustum으로 projection시켜 3D object detection을 진행
Data representation matters.
여기선 point cloud로 표현하는 것이 image-based보다 더 3D object detection의 convolution 구조에 더 적합한 이유에 대해서 설명합니다.
convolution의 기본적인 가정이 2가지 존재합니다.
1. 이웃한 pixel 끼리 의미가 있고 해당 pixel들끼리는 한 patch 안에 존재한다.
- 3D 상에서는 멀리 떨어져 있지만 2D 상에서 보면 붙어있는 경우가 있습니다. 이러한 경우에도 서로에게 영향을 주므로 불완전한 가정이다! 라고 주장합니다.
2. 모든 이웃 pixel들은 동일한 방식으로 적용된다.
- 위에서 언급하였듯 3D 상에서는 이웃한 pixel끼리 다른 depth를 가질 수 있는데 이때 같이 convolution이 진행되면 안된다고 주장합니다.
- 또한 가까이 있는 object의 경우에는 이미지 상에서 물체가 크게 보여 한 patch 안으로 안들어오는 경우도 존재합니다.
이러한 가정에 따른 문제들 때문에 image-based에서 convoluiton으로 3D object detection을 하는 것은 좋지 못한 선택이다!라고 이 논문에선 주장하고 있습니다.
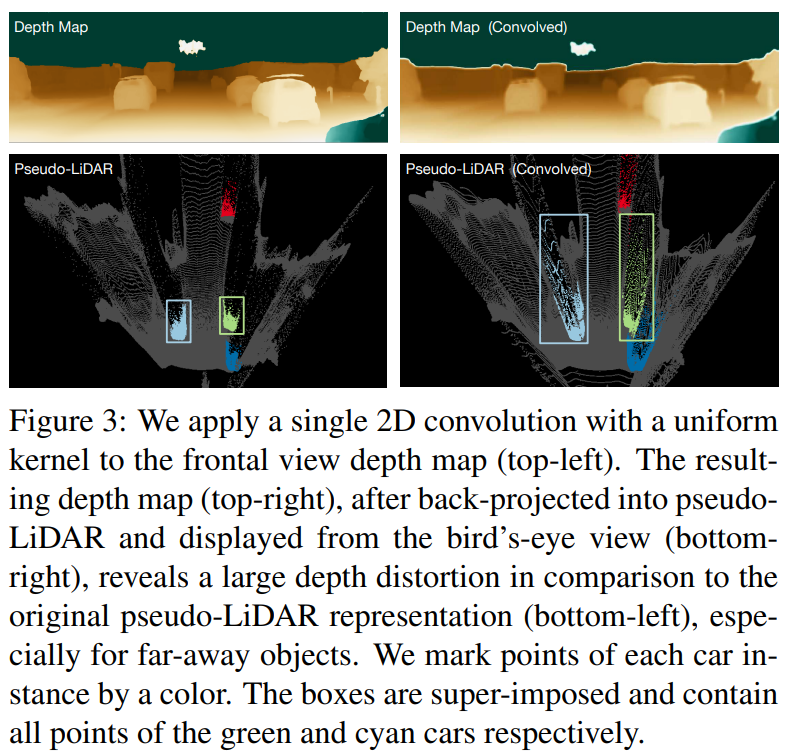
이런 convolution의 문제점을 보여준 사진입니다.
사진을 보면 convolution으로 인하여 인접한 pixel들의 다른 depth들 때문에 boundary 영역에서 긴 꼬리가 생긴 것처럼 보이게 됩니다. 이러한 문제점을 image-based 에선 가지고 있기 때문에 point cloud representation인 Pseudo-LiDAR를 사용해야 한다고 주장합니다.
Experiments
실험에 사용되는 depth estimation 모델은 아래와 같습니다.
- Monocular Depth Estimation model
- DORN (Learning based model): multi-scale feature와 여러 개의 threshold를 사용한 regression을 사용해 pixel 별로 depth를 낮은 error를 가지고 예측이 가능한 모델
- Stereo Depth Estimation model
- Learning based model
- PSMNet (Pyramid Stereo Matching Network): end-to-end로 복잡하게 놓인 사물도 정확한 stereo matching 점을 찾아 후처리 없이 depth map을 생성하는 모델
- DispNet: 가상의 data로도 잘 동작하는 모델, large dataset에서 최초로 학습 가능한 convolutional network
- Non-learning based model
- SPS-Stereo
- Learning based model
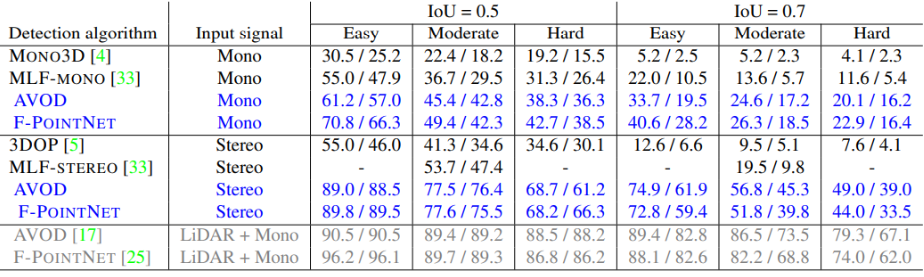
파란색으로 표시된 성능이 Pseudo-LiDAR를 사용하여 얻은 성능이고 위에 같은 경우엔 Monocular image 중간은 Stereo image로 얻은 성능입니다.
회색의 경우엔 Pseudo-LiDAR를 사용하지 않고 실제 LiDAR와 image로 얻은 결과입니다.
결과를 분석해보면 monocular image로 얻은 Pseudo-LiDAR의 성능이 Stereo의 성능보다 더 안 좋은 결과를 얻었습니다. 이를 논문에선 Stereo가 정확도가 더 높고 LiDAR 성능에 준할 수 있기 때문에 더 유망한 분야라고 주장합니다.
하지만 개인적인 생각으로는 Monocular image보다 Stereo image가 더 정확한 depth map을 뽑을 수 있기 때문에 매우 큰 성능 차이가 났다고 생각을 합니다. 따라서 이 논문에서 주장하는 부정확한 depth 때문이 아닌 representation의 문제라고는 할 수 없다고 생각합니다.
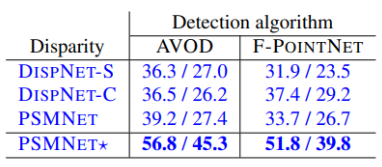
ablation study에 나온 성능 표입니다.
여기서 사용된 DispNet, PSMNet은 모두 Sceneflow dataset에서 pre-train 된 모델로 학습을 진행하였는데 PSMNet* 같은 경우에는 KITTI dataset으로 fine-tuning을 진행한 모델로 진행한 결과입니다.
이 결과를 보더라도 더 좋은 depth estimation이 결국 더 좋은 detection 성능을 낸 것을 볼 수 있습니다. 따라서 여기서 주장하는 부정확한 depth 문제가 아닌 representation의 문제라고만 하기에는 조금 어려운 부분이 있다고 생각합니다.