나의 정리
- 논문이 지적한 문제점
기존의 monocular 3D object detection으로 multi-view camera 3D object detection을 진행하려면 각각의 view 각각 detection을 진행해야 했습니다. 또한 추가적인 depth estimation network를 사용하거나 bottom-up 방식을 사용하면 compounding error로 인해 전체적인 성능의 저하를 일으킵니다. - 해결 방안
detection head layer에서 object query를 사용해 bbox의 center를 prediction하여 그 값으로 2D feature를 sampling 해서 object query에 정보를 추가해주고 multi-head attention을 통해서 2D information을 3D 상으로 학습을 시켜줍니다. 최종적으로 각각의 object query에서 bbox와 label을 예측함으로써 NMS와 같은 post-processing을 사용하지 않는 Top-down 방식을 사용합니다.
Abstract
multi-camera 3D object detection을 위한 framework DETR 3D에 대해서 소개합니다.
monocular image로 곧바로 3D BBox를 예측하거나 depth prediction network를 사용하는 기존의 방법들은 2D 정보로부터 3D object detection을 위한 input을 생성합니다.
하지만 DETR 3D는 3D space에서 곧바로 prediction을 처리합니다.
먼저 multi-camera image로 2D feature를 추출하고 camera transform matrix를 사용하여 3D 위치를 multi-view image로 projection하여 2D feature를 indexing 하기 위해서 3D object query를 사용합니다.
set-to-set loss를 사용하여 prediction과 GT와의 loss를 줄여가며 각 object query마다 하나의 bbox를 예측합니다.
이는 Top-down 방식이라 기존의 bottom-up 방식이 겪던 compounding error에 영향을 받지 않습니다. 또한 NMS를 사용하지 않기 때문에 속도가 빠릅니다.
nuScenes dataset을 이용해서 성능을 평가하였고 SOTA 성능을 냈습니다.
Introduction
기존의 depth estimation network를 사용하는 모델들은 낮은 quality의 estimated depth를 얻게 되면 이후의 3D detection 성능에 큰 악영향을 끼치는 compounding error를 겪을 수 있습니다.
따라서 DETR3D는 dense한 depth prediction을 위해 추가적인 network를 사용하지 않고 2D observation과 3D prediction 사이의 변환을 통해서 진행합니다.
이 변환은 Camera transformation matrix를 사용하여 geometric back-projection으로 2D feature extraction과 3D object prediction을 연결하는 과정입니다.
DETR3D는 point cloud reconstruction이나 추가적인 depth prediction이 없이 동작을 합니다. 또한 NMS와 같은 어떤 post-processing도 필요하지 않습니다.
Contribution을 정리하면 아래와 같습니다.
- 기존엔 각 view에서 나온 object prediction들을 마지막 단계에서만 합쳐주는데 DETR3D는 각각 layer의 계산에서 fusion을 진행합니다.
- backward geometric projection을 통하여 2D feature extractor와 3D BBox prediction을 연결하는 모듈을 소개합니다.
- per-image or global NMS와 같은 post-processing이 필요하지 않습니다. 특히 다른 모델들보다 image 상의 겹치는 부분에 대해서 성능이 매우 높은 것을 볼 수 있습니다.
Method

Overview
세가지 주요한 component를 가지고 있습니다.
- ResNet과 FPN을 사용해서 Image로부터 feature를 추출하는 component
- 주요 contribution인 geometry-aware 방식을 사용해 추출된 2D feature를 3D bbox prediction으로 연결시키는 detection head
- set-to-set loss를 사용하여 학습
Feature Learning

먼저 학습에 사용되는 data들은 multi-view camera image, camera matrix (intrinsic & extrinsic parameter가 주어져서 이를 통해 만듭니다.), GT Box (position, size, heading angle, velocity), categorical labels입니다.
ResNet과 FPN을 사용하여서 multi-scale에서의 feature를 추출합니다. 이때 다른 size의 object를 detection 하기 위한 풍부한 정보를 얻기 위해서 multi-scale (FPN)을 사용합니다.
Detection Head
기존의 방식들은 bottom-up 방식으로 detection을 진행하였습니다.
기존의 bottom-up 방식
image당 많은 bbox를 예측하고 불필요한 bbox를 NMS와 같은 post-processing을 통하여 걸러줍니다.
이후에 각각의 view에서 얻은 결과를 합쳐주는 과정입니다.
하지만 정확한 depth perception이 dense prediction을 위해 필요하고 NMS와 aggregation은 병렬 연산이 되지 않기 때문에 이 논문에서는 Top-down 방식으로 진행합니다.

위 그림의 2D-to-3D feature tranformation의 과정은 아래와 같습니다.
- object query와 관련된 bbox center의 집합을 예측합니다.
- Camera tranformation matrix를 사용하여 feature map으로 예측된 center를 projection 시킵니다.
- projection 된 위치에 bilinear interpolation을 통해 feature를 sample 하고 object query와 더해줍니다.
- multi-head attention을 사용하여 object 간의 interaction을 describe 합니다.
위 과정을 수식과 함께 보며 이해해보겠습니다.

먼저 object query를 neural network를 통과시켜 bbox center의 집합을 얻습니다.

왼쪽의 식은 homogeneous 형식을 사용하면 더 정확하기 때문에 1을 concat 해주고 m 번째 camera matrix로 projection을 시켜줍니다. 이후에 [-1, 1]로 normalize를 하고 다음 step에서 사용합니다.

bilinear interpolation으로 image feature에서 해당하는 부분의 feature를 추출해줍니다.

$\sigma_{lkmi}$ 는 image plane 밖으로 projection이 되었을 경우를 filtering 하기 위해서 사용하는 binary value이고 $\epsilon$은 0의 값이 나눠지는 경우를 위해 아주 작은 값을 사용합니다. 최종적으로 모든 k-level과 m번째 카메라들의 feature를 하나로 합쳐줍니다.
이렇게 만들어진 $f_{li}$를 object query와 더해주어 다음 level의 query를 생성합니다.

이후에 각각의 object query를 regression, classification을 위한 MLP를 통과시켜서 최종적인 bbox와 label을 예측합니다.
Loss
앞서 설명했듯 set-to-set loss를 사용합니다.
이는 class label을 위한 focal loss와 bbox parameter를 위한 L1 loss로 구성이 됩니다.
대부분의 prediction 개수는 GT의 개수보다 많으므로 GT set에 no object를 padding 해주어서 computation을 줄였다고 합니다.

DETR에서 사용했던 matching 식과 동일하게 위의 식을 사용해 bipartite matching으로 matching cost를 계산하게 됩니다.

그다음 과정으로는 위에서 매칭 한 prediction과 GT와 Hungarian algorithm을 사용해서 최적의 assign을 찾아주게 됩니다.
Experiments
Implement Details
backbone으로 ResNet을 사용하였고 이때 FPN을 사용해서 mulit-scale level의 feature map을 사용합니다.
이때 deformable convolution을 사용하는 ResNet101을 3번째, 4번째 stage에서 사용하고 FPN으로 $\frac{1}{8},\frac{1}{16},\frac{1}{32},\frac{1}{64}$ 4가지의 size를 가지는 feature map을 사용합니다.
DETR3D의 detection head는 6개의 layer를 가지고 있는데, 각각의 layer는 feature refinement 과정과 multi-head attention layer의 조합으로 이루어져 있습니다. detection head 마지막에서 2개의 sub-network를 사용하여 bbox parameter와 class label을 각각의 object query마다 예측을 진행합니다.

기존의 다른 방식들과의 비교 table입니다. 기존의 monocular 3D object detection은 multi-view에 적용하려면 각각의 view에 따로 진행해야 하는 단점이 존재합니다. 하지만 DETR3D은 multi-view를 한 번에 사용하여 매우 효율적입니다.

다음은 multi-view camera에서 각각의 view가 일정 영역 겹치게 되는데 그 부분에 대한 비교입니다. 이 부분에 대해서도 DETR3D는 multi-view를 한번에 사용하므로 여러 view에 대해 overlap이 되어 object가 잘리는 현상에 대해서 효율적으로 처리가 가능하다고 합니다.

다음은 Pseudo-LiDAR 방식과의 비교입니다. 매우 큰 성능 차이를 가지고 있는 것을 볼 수 있습니다. 이는 Pseudo-LiDAR가 겪는 compounding error를 DETR3D는 겪지 않기 때문이라고 설명합니다.

다음은 detection head의 각 layer마다 진행되는 refinement에 대한 실험입니다. 위 그림을 보면 layer가 깊어짐에 따라 예측되는 bbox가 Ground Truth에 가까워지는 것을 볼 수 있고 table 5를 봐도 NDS가 layer가 깊어짐에 따라 점점 오르는 것을 볼 수 있습니다.
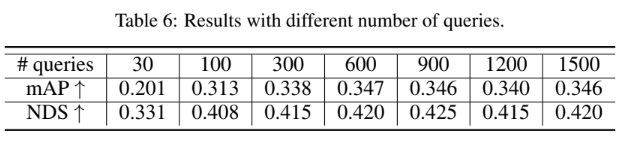
또한 object query의 개수에 대한 실험도 진행하였는데 900개에서 saturate 되었다고 합니다. 이전 DETR 논문을 보면서 object query가 anchor처럼 많은 수를 가져가는 게 좋지 않을까란 생각을 하였는데, 이 실험을 보면 적당한 양을 실험을 통해서 가져가는 것이 좋을 수 있다는 것을 알게 되었습니다.