나의 정리
- 논문이 지적한 문제점
Monocular 3D detector는 LiDAR-based 3D detector와 비교하여 성능 차이가 존재합니다.
또한 Monocular Depth estimation으로 생성된 depth map의 경우 부정확한 depth를 추정하기 때문에 estimated depth map으로 Pseudo-LiDAR를 생성하면 noisy 한 point들이 생성됩니다. 따라서 noisy에 대한 고려가 필요합니다. - 해결 방안
Pseudo-LiDAR는 global structure에 대해서는 잘 생성되지만 local noise가 존재하기 때문에 Point Cloud Frustum을 생성하면 local misalignment가 생깁니다. 이러한 문제를 2D-3D consistency loss를 이용하여 해결합니다. 또한 object의 boundary 근처의 depth에 대해서는 부정확한 값을 예측하게 되어서 point들이 object 근처에 long-tail의 형태로 생기게 됩니다. 이때 2D proposal을 bounding box representation을 사용하게 되면 object가 아닌 부분의 point들도 frustum에 포함되게 됩니다. 따라서 좀 더 tight 한 예측이 가능한 instance mask를 사용하여 해당 문제를 완화하였습니다.
2019 ICCVW에 발표된 Pseudo-LiDAR에 대한 논문을 읽어봅니다.
같은 해 2019 CVPR에 발표된 또 다른 Pseudo-LiDAR 논문과 비교해서 더 많은 Pseudo-LiDAR에 대한 분석과 실험이 들어가 있고 더 높은 성능을 가지고 있습니다.
Abstract
이 논문은 기존 LiDAR-based 3D detector와 monocular image-based 3D detector와의 성능 차이를 줄이는 것에 목적을 두었습니다.
성능 차이를 줄이기 위해서 monocular depth estimation을 통해서 depth map을 구한 뒤 해당 depth map으로 point, 즉 Pseudo-LiDAR를 생성하여 사용합니다.
하지만 depth map으로 생성된 Pseudo-LiDAR의 경우 매우 많은 양의 noise가 존재합니다. 따라서 두 가지 해결 방안을 제시합니다.
- 예측한 3D bbox를 2D로 projection 시켜서 2D proposal과 비교하여 2D proposal을 따라갈 수 있게 끔 consistency loss를 추가 합니다.
- Point cloud 중 object에 포함되지 않는 point 수, 즉 불필요한 point를 제거하기 위해서 instance mask (segmentation mask)를 사용합니다.
KITTI dataset으로 평가하였고 높은 성능을 냈습니다.
Introduction
지금까지 3D object detection은 depth camera나 stereo camera, laser scanner (LiDAR) 등에 의존하여 왔습니다. 하지만 이러한 sensor들에도 한계점이 존재합니다.
- depth camera의 경우 동작 가능한 depth의 범위가 한정적입니다.
- 여러 개의 sensor를 사용하는 경우 synchronization이나 calibration 과정이 필요합니다.
- LiDAR 같은 경우 멀리 있는 object까지 정확하게 탐지가 가능하지만 가격이 매우 비쌉니다.
이러한 한계점들로 single camera로 3D object detection을 진행하는 연구가 필요합니다.
single image로 depth estimation model을 통해 얻은 depth map을 camera matrix를 이용하여 Pseudo-LiDAR를 생성합니다.
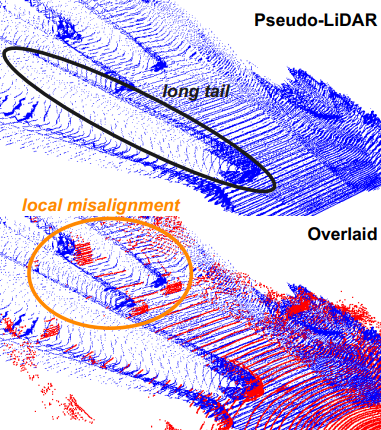
하지만 생성된 Pseudo-LiDAR는 부정확한 depth estimation으로 인하여 많은 noise가 존재합니다.
위 그림은 파란색 point가 Pseudo-LiDAR, 빨간색 point가 실제 LiDAR data입니다.
- Local misalignment
Pseudo-LiDAR로 point cloud frustum을 생성하게 되는데 생성된 point cloud frustum이 실제 LiDAR와 비교하였을 때 misalignment가 됩니다. 또한 멀리 있을수록 local misalignment가 심해지는 문제가 발생합니다. 이러한 문제는 object의 center를 예측하는데 악영향을 끼치게 됩니다.
→ misalignment를 해결하기 위해서 2D-3D consistency Loss를 사용하여 해결합니다. - Long tail
object의 boundary 근처는 depth estimation이 정확하지 않아서 이러한 부분에 point들이 부정확하게 생기는 문제가 발생합니다. 그림을 보면 object에 긴 꼬리(long-tail)가 생긴 것처럼 보이는 문제가 발생합니다. 이러한 문제는 point cloud frustum 생성 시 redundant 한 point들을 많이 포함하게 되는 문제로 이어집니다.
→ 물체에 포함되지 않는 point들을 줄이기 위해서 instance mask를 사용하여 해결합니다.
이 논문의 Contribution을 정리하면 다음과 같습니다.
- Pseudo-LiDAR를 사용하여 monocular 3D object detection을 진행하는 pipeline을 제안합니다.
- Pseudo-LiDAR에 존재하는 noise를 완화시켰습니다.
- consistency loss를 사용하여 Pseudo-LiDAR의 misalignment를 줄였습니다.
- 2D propoal을 bbox 형태가 아닌 instance mask 형태로 사용하여 redundant point를 줄였습니다.
- KITTI에서 SOTA 성능을 냈습니다.
Related Work
같은 해인 2019년에 CVPR에도 Pseudo-LiDAR를 사용하는 논문이 존재합니다.
Pseudo-LiDAR from Visual Depth Estimation: Bridging the Gap in 3D Object Detection for Autonomous Driving (2019, CVPR)
[논문 리뷰] Pseudo-LiDAR from Visual Depth Estimation: Bridging the Gap in 3D Object Detection for Autonomous Driving (2019)
나의 정리 논문이 지적한 문제점 기존의 monocular 3D detection의 경우 많은 논문들이 depth 정보를 만들어내 detection을 진행하는데 이 때 부정확한 depth 정보를 만들어 내기 때문에 LiDAR detector에 비해
talktato.tistory.com
위의 논문에서는 image-based가 아닌 point-based가 3D object detection에 더 잘 어울리는 representation이라고 설명하면서 Pseudo-LiDAR를 그냥 사용합니다.
하지만 이 논문에서는 Pseudo-LiDAR를 생성하고 더 개선하여 더 높은 성능을 냈습니다.
→ misalignment, long-tail 문제를 완화시켰습니다.
Method
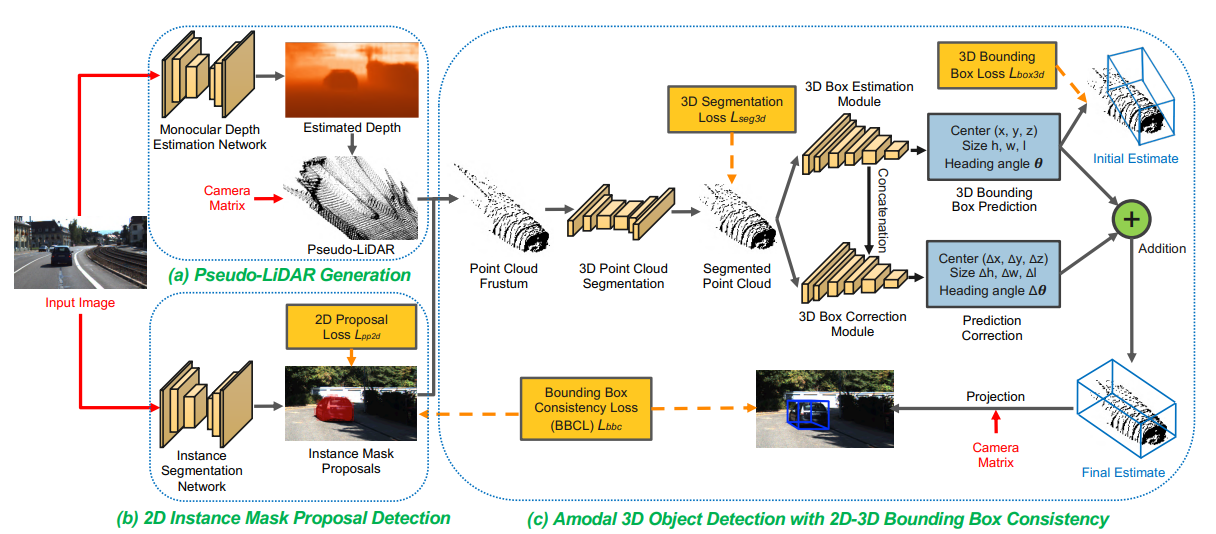
모델의 overall architecture는 위와 같습니다.
Training, Testing에서 오로지 single RGB image만을 사용합니다.
먼저 single image로 DORN(monocular depth estimation model)을 이용해 depth map을 얻고 estimated depth map으로 camera matrix를 사용해 Pseudo-LiDAR로 변환합니다. 또한 image를 Mask RCNN(2D segmentation model)을 이용해서 2D proposal을 instance mask 형태로 얻습니다.
이후에는 LiDAR-based model인 Frustum PointNets을 사용하여 3D object detection을 진행합니다. 먼저 instance mask를 이용해서 Point Cloud Frustum을 생성한 뒤 3D Point Cloud segmentation을 진행합니다. (이는 Frustum PointNet에서 사용되는 방식입니다.)
그다음 3D Box estimation을 진행하는데 이때 3D box Correction module을 통해서 consistency loss를 통해 얻은 정보로 3D box를 refinement 하는 방식으로 진행됩니다. 최종적으로 3D box와 2D proposal을 consistency loss를 이용해 학습합니다.
Pseudo-LiDAR Generation
Monocular Depth Estimation.
monocular depth estimation으로 DORN 모델을 사용합니다.
pretrain 된 model을 사용하고 training시에 weight를 update 하지 않는 방식으로 학습이 진행됩니다.
Pseudo-LiDAR Generation.
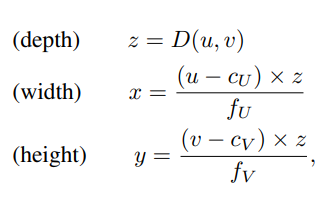
estimated depth map을 Pseudo-LiDAR로 만들어주는 과정입니다.
위의 식은 Camera matrix로 얻을 수 있는 식이고 depth는 depth map으로 얻은 값으로 사용합니다.
Pseudo-LiDAR vs. LiDAR Point Cloud.
여기선 Pseudo-LiDAR와 LiDAR의 차이를 확인해보며 noise에 대한 고찰을 합니다.
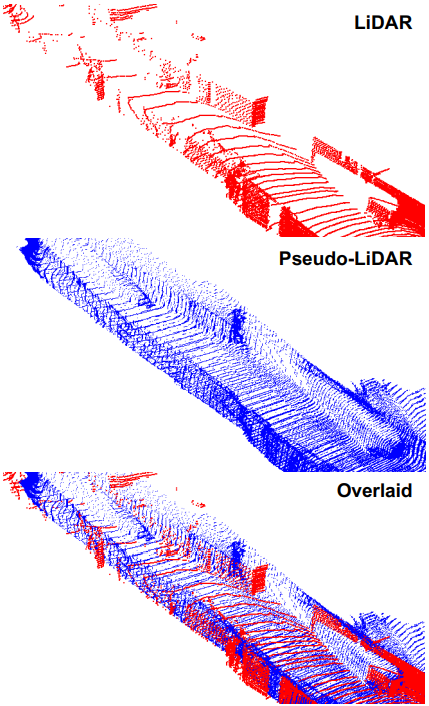
Overlaid 그림을 보면 Pseudo-LiDAR는 global structure에 대해서는 잘 생성하지만 local noise가 매우 큰 것을 확인할 수 있습니다. 이러한 noise가 주는 영향으로 두 가지가 존재합니다.
- Point Cloud Frustum 생성 시 기존 LiDAR와 비교하였을 때 멀리 떨어져 있을 수 있어서 local misalignment가 생길 수 있습니다. 이는 곧 center localization에 악영향을 끼칠 수 있습니다.
- 물체의 boundary 영역의 depth estimation이 정확하지 못해 long-tail이 생기게 됩니다. 이는 object size를 추정하는데 악영향을 끼칠 수 있습니다.
또한 Pseudo-LiDAR가 LiDAR와 비교하여 보았을 때 훨씬 dense 한 것을 볼 수 있습니다. 이 density에 대한 실험도 이후에 Experiments에서 비교해보며 실험할 예정입니다.
2D instance Mask Proposal Detection
이전까진 2D proposal을 bounding box로 사용하였습니다. 하지만 noisy 한 Pseudo-LiDAR에서 boudning box를 사용하여 Point Cloud Frustum을 얻게 되면 수많은 쓸모없는 point들이 포함되게 됩니다.
따라서 좀 더 tight 하게 사용할 수 있는 instance mask를 사용하는 것이 더 좋다고 합니다.

위의 그림을 보면 bounding box로 Point Cloud Frustum을 생성하는 경우에 long tail을 모두 포함하게 되어 실제 object가 아닌 부분들도 포함이 되게 됩니다.
하지만 좀 더 tight 한 예측을 하는 instance mask의 경우에 많은 noisy point를 제거할 수 있는 것을 볼 수 있습니다.
Amodal 3D Object Detection
3D object detection을 하기 위해서 LiDAR-based 3D detector인 Frustum PointNets을 사용하여 3D box $(x, y, z, w, h, l, \theta)$를 예측합니다.
2D-3D Bounding Box Consistency (BBC)
3D bounding box가 정확하지 않으면 projection 시킨 2D box와 2D proposal이 잘 match 되지 않습니다. 이러한 local misalignment를 해결하기 위해서 BBC를 사용합니다.
먼저 3D bounding box를 2D로 projection을 시켜야 합니다. 이때는 아래와 같은 순서로 진행됩니다.
- $(x, y, z, w, h, l, \theta)$를 8-corner representation으로 변경합니다.
- camera projection matrix로 8개 코너를 각각 2D로 projection 하여 8개의 2D 점을 얻습니다.
- Minimum Bounding Rectangle (MBR)을 이용하여 $(t_x,t_y,t_w,t_h)$를 구합니다.
- 2D mask proposal도 MBR을 이용하여 똑같이 $(t_x,t_y,t_w,t_h)$를 구합니다.
위에 방법으로 얻은 두 개의 2D bounding box를 2D IOU를 구해서 사용합니다.
- 8-corner representation
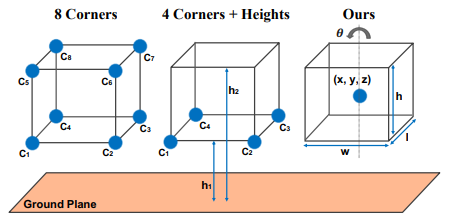
- MBR이란?
최소 경계 사각형으로 위와 같이 점들이 존재할 때 점들을 모두 포함하는 가장 작은 사각형을 구하는 방법입니다.

Bounding Box Consistency Loss (BBCL).
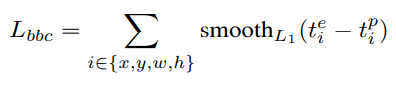
$t_i^e$는 3D bbox를 2D로 projection 시킨 값이고 $t_i^p$는 2D mask proposal을 2D box로 만든 값입니다. 위와 같이 projection 시킨 값이 2D proposal과의 차이를 regression을 통해서 따라가게 학습을 합니다.
Bounding Box Consistency Optimization (BBCO).
학습이 아닌 평가를 할 때 post-processing 단계로 BBCO를 진행합니다.
예측한 3D bounding box와 2D proposal 쌍에 대해서 같은 optimization problem을 해결하고 Global Search Optimization method를 이용해서 $L_{bbc}$를 최적화합니다.
→ 3D bounding box를 refinement 하기 위한 방법입니다.
Experiments
Monocular Depth Estimation model로 DORN, Instance Segmentation model로 Mask RCNN, LiDAR-based 3D detector로 Frustum PointNets을 사용하였습니다.
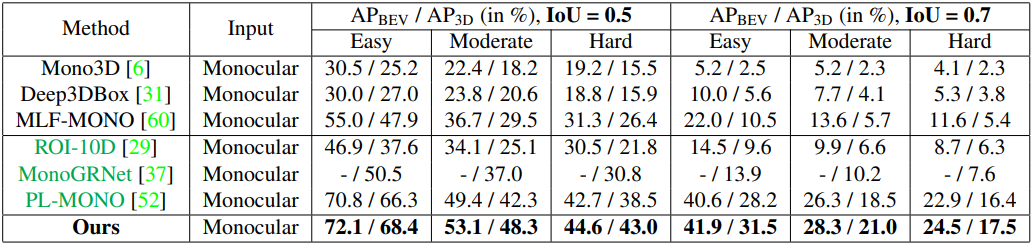
다른 SOTA model과 비교해서 더 높은 성능을 가집니다.
Ablation Study
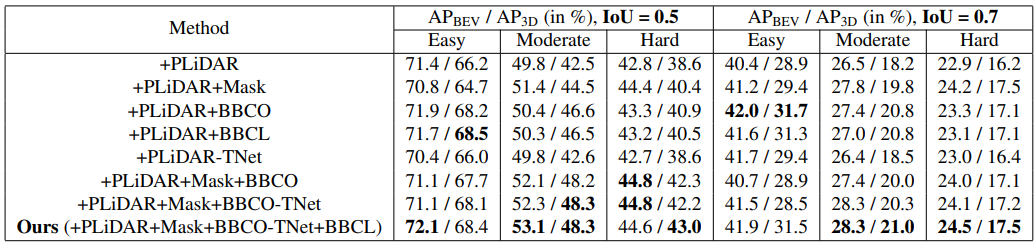
Ablation study로 각 module에 대한 성능 gain을 확인할 수 있습니다.
성능을 확인해보면 Instance mask를 사용하는 것이 확실히 많은 gain을 얻을 수 있다는 것을 볼 수 있습니다.
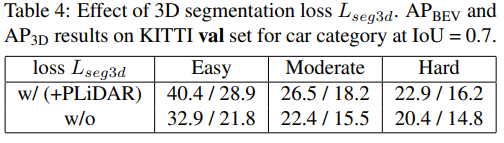
3D segmentation으로 direct supervision을 주는 것의 효과를 입증하기 위한 실험입니다. 확인을 해보면 확실히 성능이 크게 떨어지는 것을 볼 수 있습니다.
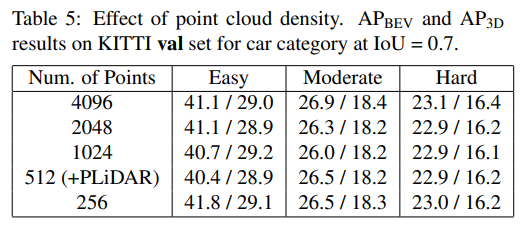
가장 궁금했던 Pseudo-LiDAR의 dense 한 것이 어떤 도움이 될까? 에 대한 답을 찾을 수 있었던 실험입니다. 실험을 보면 Pseudo-LiDAR로 생성된 Point를 몇 개를 sampling하여 학습 했는지에 따른 성능이 나와있습니다.
성능을 보면 알 수 있다시피 4096에서 256까지 아주 낮은 숫자를 가지고 사용하더라도 큰 성능 차이가 없는 것을 볼 수 있습니다. 이를 통해서 Pseudo-LiDAR는 dense한 point를 가지고 있지만 noisy 한 point를 많이 가지고 있기 때문에 point 수를 많이 줄여도 성능에 대한 차이가 크게 없는 것을 확인할 수 있었습니다.