나의 정리
- 논문이 지적한 문제점: 기존의 Voxel 기반의 3D object detection인 VoxelNet에서 sparse 한 data인 LiDAR data에 convolution을 적용하다 보니 계산량이 많아 느린 단점과 orientation의 예측 성능이 낮은 문제점이 존재합니다.
- 해결 방안: Sparse한 data의 특성에 맞춰서 기존의 dense convolution이 아닌 sparse convolution을 이용하고 fast rule generation을 통하여 더 빠른 학습과 추론이 가능하게 하였습니다. 또한 기존의 angle regression loss 문제점을 지적하고 novel angle regression loss와 direction classifier를 통하여 orientation 예측 성능을 높였습니다. 마지막으로 data augmentation을 통하여 convergence 속도를 높이고 AP를 더 높였습니다.
Abstract
Voxel 기반의 3D convolutional network들은 LiDAR point cloud data를 사용해 정보를 강화시키기 위해서 사용되어 왔습니다. 하지만 느린 inference time과 orientation 예측 성능이 낮은 문제점이 존재합니다. 따라서 학습과 추론의 속도를 많이 개선시킨 sparse convolution method를 제안합니다.
새로운 angle loss regression 형식을 통해 orientation 예측 성능을 개선했고 새로운 data augmentation방식을 통하여 convergence 속도와 성능을 강화하였습니다.
SECOND는 KITTI 3D object detection에서 빠른 inference 시간을 가지고 SOTA 성능을 냈습니다.
Introduction
현재 많은 3D detector들은 image와 point cloud data를 fusion 하는 방식을 많이 사용하고 있습니다.
point cloud data를 BEV image로 바꾸거나 image 위로 projection 시켜서 fusion을 진행합니다.
2D detector를 이용해 생성된 bbox를 통해 point cloud data를 필터링하고 point를 직접적으로 convolution network에 넣어 사용하는 방법도 있습니다.
다른 방식으로는 point cloud data를 해당하는 voxel에 할당한 뒤 3D CNN을 진행하는 방법도 존재합니다.
→ VoxelNet
가장 최근에 방식인 VoxelNet은 먼저 point cloud data들을 해당하는 voxel로 grouping을 진행하고 linear network를 voxel 별로 거친 뒤 voxel을 3D tensor로 변환하여 RPN에서 사용하는 방식입니다. 이러한 방식은 3D convolution을 이용하기 때문에 계산 비용이 커서 real-time이 보장되어야 하는 곳에서는 사용이 되기 어렵다는 문제점이 있습니다.
따라서 point cloud data의 풍부한 3D information을 최대로 사용하는 SECOND(Sparsely Embedded CONvolutional Detection)을 제안합니다. SECOND는 다른 dense convolution network와 비교하였을 때 4배 빠른 train 속도와 3배 빠른 inference 속도를 가진다고 합니다.
point cloud data를 사용하는 또 다른 장점은 scale, rotation, translate와 같이 object에 해당하는 특정 point에 곧바로 transformation을 적용하여 augmentation이 쉽다는 것 입니다.
이러한 속성을 이용해 새로운 data augmentation 형식으로 객체의 속성과 관련된 point cloud를 포함하는 GT data-base를 생성하게 됩니다.
추가적으로 앞서 언급했던 angle loss regression을 새롭게 정의하여 GT와 prediction의 angle이 $\pi$ 만큼 차이 날 때 큰 loss가 생성되는 문제를 해결하였습니다. 또한 보조 direction classifier를 사용하였습니다.
최종적으로 SECOND의 key contribution을 정리하면 아래와 같습니다.
- 학습과 추론 시간을 크게 줄인 sparse convolution을 LiDAR-based object detection에 적용했습니다.
- 빠르게 동작하기 위해 개선된 sparse convolution을 제안합니다.
- orientation regression 성능을 높이기 위해서 novel angle loss regression을 제안합니다.
- LiDAR-only learning의 문제점인 convergence 속도와 성능을 크게 개선하기 위한 방법인 novel data augmentation을 제안합니다.
Related Work
생략
SECOND Detector

Network Architecture
위의 사진이 SECOND의 전체적인 구조입니다. 자세히 보시면 세 가지 component로 구성이 되어있습니다.
- A voxelwise feature extractor
- A sparse convolutional middle layer
- RPN (Region Proposal Network)
이후에 VoxelNet에 대한 내용이 계속 나오므로 아직 안 읽어 봤다면 한번 가볍게 읽어보는 것을 추천드립니다.
https://talktato.tistory.com/14?category=1069578
[논문 리뷰] VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection
나의 정리 기존의 hand-crafted feature가 아닌 feature extraction과 bbox prediction이 one-stage로 합쳐진 end-to-end 학습이 가능한 deep architecture이다. sparse 한 data인 point cloud를 바로 사용하여 sp..
talktato.tistory.com
1.1. Point Cloud Grouping
이전에 review 했던 VoxelNet에서 사용했던 grouping 과정을 비슷하게 거치게 됩니다.
먼저 최대 voxel의 개수를 특정한 값으로 정해놓고 buffer를 사전에 할당을 해줍니다. 그 이후에 point cloud들을 순회하면서 해당 point가 포함되는 voxel로 point를 할당해줍니다. 또한 각 voxel 마다 point의 개수와 voxel의 좌표를 저장하게 됩니다.
위의 과정에서 hash table을 기반으로 voxel의 존재를 확인합니다. 만약 point와 관련된 voxel이 아직 생성되지 않았다면, 해당하는 값을 hash table에 생성하게 됩니다. 이러한 반복을 앞서 말한 최대 voxel 개수까지 진행하게 됩니다.
모든 task에서 voxel size를 $v_D=0.4m,v_H=0.2m,v_W=0.2m$ 를 사용합니다.
Car detection의 경우 각 voxel의 maximum point 개수는 $T = 35$ 로 사용합니다.
하지만 Pedestrian, Cyclist의 경우엔 비교적으로 더 작은 객체이기 때문에 더 많은 point가 필요해 $T = 45$ 로 사용한다고 합니다.
1.2. Voxelwise Feature Extractor
이 부분 또한 VoxelNet과 매우 유사한 형태로 사용합니다.

Voxel-wise feature를 추출해 내기 위해서 Voxel Feature Encoding (VFE) layer를 사용합니다. VFE는 input으로 같은 voxel 내의 모든 point를 사용하고 pointwise feature를 추출하기 위해 Linear layer, Batch normalization layer, ReLU layer를 포함하는 FCN layer를 사용합니다.
→이해가 안된다면 VoxelNet 리뷰에서 Stacked Voxel Feature Encoding 부분을 참조.
그 이후에 각 voxel의 locally aggregated feature를 구하기 위해 element-wise max pooling을 사용합니다.
최종적으로 feature들을 늘어놓은 다음 locally aggregated feature와 point-wise feature를 concatenate 해줍니다.
1.3. Sparse Convolutional Middle Extractor
Sparse Convolution Algorithm
먼저 2D dense convolution alogorithm을 먼저 생각해보면 식은 아래와 같습니다.

u, v는 spatial location index를 의미하고 l은 input channel, m은 output channel을 나타낼 때 $W_{u,v,l,m}$ 은 filter의 각 원소들을 나타내고 $D_{u,v,l}$ 은 image의 원소를 나타냅니다. x, y가 output spatial index이고 $u - u_0, v - v_0$ 는 u, v 좌표에서 kernel offset을 추가한 것을 나타냅니다.
img2col이라고 알려진 General Matrix Multiplication (GEMM)-based algorithm을 사용해서 input image를 column matrix으로 만든 뒤 filter matrix를 곱하여서 사용합니다. 식은 아래와 같습니다.

$W_{*,l,m}$ 은 $W_{u-u_0,v-v_0,l,m}$ 을 GEMM 형식으로 바꾼 것을 의미합니다.
이런 연산을 sparse data인 $D_{i,l}'$ 을 활용해서 다시 sparse convolution을 진행하면 식은 아래와 같습니다.
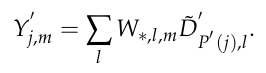
$P'(j)$ 는 input index i와 filter offset을 구하기 위한 함수입니다. 또한 sparse data를 모은 matrix인 $D'_{P'(j),l}$ 은 여전히 많은 0을 포함하고 있으므로 모두 계산할 필요가 없습니다.

따라서 0이 아닌 data에서만 수행하면 되므로 최종적으로 위와 같은 식을 사용하여 Sparse convolution을 수행하게 됩니다.
GEMM이란?
딥러닝에서 대부분의 연산은 output = input * weight + bias로 표현을 할 수 있습니다.
하지만 convolution을 최적화하여 수행하기 위해서 GEMM을 사용할 수 있습니다.
GEMM의 가장 일반화된 식은 아래와 같습니다. $C = \alpha AB + \beta C$ 먼저 input image를 행렬(col)의 형태로 변환을 하여 filter matrix와 연산을 통해 output을 얻게 됩니다.
정리하면 1. input을 col로 바꾸기 2. filter와 col의 GEMM 계산으로 GEMM-convolution을 진행합니다.
이를 통하여 convolution을 최적화해 빠른 연산이 가능하게 된다.
다시 본론으로 돌아와서 위의 수식에서 $R_{k, j}$ 는 Rule이라고 칭합니다. 이는 kernel offset k와 output index j로 input index i를 특정화하는 matrix를 의미합니다.
실제로 GEMM을 수행하기 위해서 input-output index rule matrix를 통하여 sparse 한 original data에서 바로 data를 만들어 줍니다. 이러한 과정을 통하여 속도를 높일 수 있었다고 합니다.
rule matrix에 대해서 더 설명을 해보겠습니다.
원래의 sparse한 data를 모아주는 gather 과정을 한번 수행해주고 원래의 sparse한 형태로 흩뿌려주는 scatter 과정을 한번 수행해 주어야 합니다.
rule matrix table $R_{k, i, t} = R[k, i, t]$ 의 차원은 $K \times N_{in} \times 2$ 입니다. K는 kernel size, $N_{in}$ 은 input feature의 개수, t는 input/output index를 의미합니다. 따라서 R[:, :, 0]에는 input index들이 gathering을 위해서 저장되어있고, R[:, :, 1]에는 output index들이 scattering을 위해서 저장됩니다.

sparse convolution algorithm 과정을 담은 그림입니다.
Rule Generations Algorithm
이제 Rule이 어떻게 생성되는지 알아보겠습니다.
input point들을 반복하면서 각각의 input point와 관련된 output을 찾고 해당하는 index들을 rule에 저장하는 방법으로 진행됩니다. 총 3번의 Loop로 구성이 되는데 하나씩 자세히 보겠습니다.
먼저 Loop 1에선 output index 대신 input index와 associated spatial index를 수집합니다. 중복된 output location은 이 과정에서 얻어집니다. 그리고 spatial index를 통해서 output index와 output index에 관련된 spatial index를 구합니다.

Loop 2에선 다음 단계에 쓰일 table lookup을 위해서 이전 결과에서 생성된 sparse data와 동일한 spatial dimension을 가지는 buffer를 생성합니다.

Loop 3에선 마지막으로 rule을 반복하면서 각각의 input index에 해당하는 output index를 얻기 위해 저장된 spatial index를 사용합니다.

Sparse Convolutional Middle Extractor

middle extractor는 z축의 정보를 학습하고 sparse 3D data를 2D BEV image로 변환하기 위해서 사용합니다.
위에서 노란색 박스는 sparse convolution을 의미하고 이는 z 축을 downsampling 하기 위해서 사용하고 흰색 박스는 submanifold convolution을, 빨간색 박스는 sparse-to-dense layer를 의미합니다. 만약 z 축에 대한 downsampling이 진행된 뒤 dimension이 1이나 2라면 sparse data는 dense feature map으로 변환됩니다.
그 이후 data를 2D image data 형식으로 reshape 합니다.
1.4. Region Proposal Network

Region Proposal Network의 구조를 single shot multibox detector(SSD)에서 쓰인 RPN 구조로 사용합니다. 총 세 개의 stage로 구성이 됩니다.
각각의 stage는 downsampling을 위한 convolutional layer로 시작하여 몇 개의 convolutional layer를 더 거치게 되고 그 이후엔 batch norm, ReLU layer를 거칩니다.
그리고 feature map과 같은 크기로 각각의 stage의 output을 upsampling을 진행해주고 이러한 feature map들을 하나의 feature map으로 합쳐줍니다. 최종적으로 세 개의 1 x 1 convolution을 통해서 class, regression offset, direction을 예측하게 됩니다.
1.5. Anchors and Targets
검출되는 물체는 대략적으로 고정된 크기를 가지기 때문에 KITTI training set에서 0도와 90도 회전된 GT의 중심 위치와 크기의 평균을 기반으로 고정된 크기의 anchor를 사용합니다.
Car의 경우 $w=1.6\times l =3.9\times h=1.56m,\space centered\space at\space z = -1.0m.$
Pedestrian의 경우 $w=0.6\times l =0.8\times h=1.73m,\space centered\space at\space z = -0.6m.$
Cyclist의 경우 $w=0.6\times l=1.76\times h=1.73m,\space centered\space at\space z = -0.6m.$ 의 크기를 가지는 anchor를 사용합니다.
각각의 anchor는 one-hot vector of classification target과 7-vector box regression target, one-hot vector of direction classification target에 할당되게 됩니다.
서로 다른 class는 matching과 nonmatching을 위한 서로 다른 threshold를 사용합니다.
Car는 IoU threshold로 0.6을 사용하고 0.45보다 작다면 background로 간주하고 0.45와 0.6 사이는 training 동안에는 무시합니다.
Pedestrian과 Cyclist는 0.35의 nonmatching threshold, 0.5의 matching threshold를 사용합니다.

regression target을 구하기 위한 식은 위와 같습니다.
w, l, h는 각각 width, length, height를 의미하고 $\theta$ 는 z 축을 기준으로 yaw 회전 각도이고 t, a, g는 각각 encoded value, anchor, GT를 의미하고 $d^a=\sqrt{(l^a)^2+(w^q)^2}$ 입니다.
2.1. Loss
Sine-Error Loss for Angle Regression
VoxelNet에서 사용하던 angle regression에는 단점이 존재합니다.
예를 들어 direction이 0과 $\pi$ 로 prediction이 된 경우엔 같은 Box를 예측해 내지만 angle regression에서 매우 큰 loss를 생성하게 됩니다.
이러한 문제를 해결하기 위해서 새로운 angle loss regression을 제안합니다.

먼저 수식은 위와 같습니다. (p는 예측된 값을 의미합니다.)
이러한 angle loss는 두 가지 이점을 갖습니다.
- 위에서 언급한 adversarial example 문제(방향이 0, $\pi$ 인 경우)를 해결합니다.
- angle offset function을 고려해 IoU를 자연스럽게 modeling 합니다.
반대 방향의 상자를 동일한 것으로 취급하는 문제를 해결하기 위해 RPN의 output에 간단한 direction classifier를 추가하였습니다. classifier를 학습시키기 위해서 direction classifier target을 만들어야 합니다. Ground Truth의 z 축 기준 yaw의 회전이 0보다 크다면 positive, 그렇지 않다면 negative로 target을 생성하여 학습을 진행합니다.
Focal Loss for Classification
classification은 RetinaNet에서 소개된 Focal Loss를 사용합니다.
그 이유는 KITTI point cloud를 ~70k 가까이 되는 개수의 anchor를 생성하게 되는데 이렇게 생성된 anchor 중 상당한 수가 negative가 됩니다. 따라서 foreground와 background class의 심각한 class imbalance 문제가 발생하기 때문입니다.

Focal Loss는 위의 식과 같고 $\alpha = 0.25, \gamma = 2$ 로 training을 진행합니다.
Total Training Loss
최종적으로 사용하는 Loss의 식은 아래와 같습니다.

$L_{cls}$ 는 Classification Loss, $L_{reg-other}$ 는 location과 dimension을 위한 Regression Loss, $L_{reg-\theta}$ 은 위에서 소개한 novel Angle Loss, $L_{dir}$ 은 direction classification Loss이고 $\beta_1=1.0,\beta_2=2.0,\beta_3=0.2$ 로 학습을 진행합니다.
네트워크가 물체의 방향을 인식하기 어려운 경우를 대비해서 $\beta_3$ 을 상대적으로 작은 값으로 사용합니다.
2.2. Data Augmentation
Sample Ground Truths from the Database
주요한 문제는 training 과정에서 사용되는 Ground truth의 개수가 너무 적어서 수렵 속도와 최종 성능의 상당한 한계가 생기는 것입니다.
이런 문제를 해결하기 위해서 새로운 data augmentation 방법을 제시합니다.
먼저 모든 GT label과 그와 관련된 point cloud data를 담은 database를 생성합니다. 이후에 학습 과정에서 몇 개의 GT를 random 하게 골라서 현재 학습 중인 point cloud에 concat 하여 학습을 진행합니다.
concat 한 이후에 추가한 GT가 기존에 존재하던 GT들과 물리적 충돌이 일어날 수 있습니다. 따라서 충돌 test를 진행한 뒤 만약 기존 GT와 추가한 GT가 충돌한다면 삭제한 뒤 학습을 진행합니다.
Object Noise
VoxelNet에서 사용한 방식과 동일한 방식으로 noise를 줍니다. GT와 그에 해당하는 point cloud에 각각 다른 parameter를 가지고 독립적으로 random rotation, random transformation을 진행합니다.
이때 random rotation은 $[-\pi/2, \pi/2]$ 범위의 uniform distribution을 사용하고 random transformation은 평균 0, 표준 편차 1을 가지는 gaussian distribution을 사용합니다.
Global Rotation and Scaling
[0.95, 1.05]의 범위를 가지는 uniform distribution의 global scaling, $[-\pi/4,\pi/4]$ 의 범위를 가지는 uniform distribution의 global rotation을 진행합니다.
Experiments
KITTI dataset을 이용해 학습을 진행했고 3D object detection, BEV object detection bench mark에서 평가하였습니다.
Evaluation Using the KITTI Test Set

SECOND는 only LiDAR data만 사용한 방법 중엔 SOTA 성능을 찍었고 VoxelNet과 비교하였을 땐 엄청난 차이로 높은 성능을 냈습니다. F-PointNet의 경우엔 2D detector도 따로 사용했기 때문에 SECOND보다 더 높은 성능을 가졌다고 합니다.
Evaluation Using the KITTI Validation Set

Time을 보면 훨씬 빠른 속도로 높은 성능을 낸 것을 볼 수 있습니다.
Analysis of the Detection Results
Car Detection


위의 사진은 Car detection의 분석을 위한 image와 point cloud입니다. 각 색깔의 box가 의미하는 점을 먼저 설명하겠습니다.
image
“V”, “P”, “C”는 각각 Car, Pedestrian, Cyclist
Green box : 검출에 성공한 box
Red box : 낮은 정확도를 가진 검출 결과
Gray box : False negative (검출해야 하는 객체이지만 검출하지 못한 경우)
Blue box : False positive (틀린 검출)
point cloud
Green box : Ground truth
Blue box : 검출 결과
이제 Car detection에 대해서 분석을 해보면, 먼저 가까운 거리와 moderate의 경우 매우 좋은 결과를 냄을 볼 수 있습니다.
또한 거리가 좀 멀어 point가 얼마 없더라도 꽤 좋은 성능을 냄을 볼 수 있습니다. overlapping의 정도가 심한 car에 대해서도 검출이 잘 되는 것을 볼 수 있습니다.
하지만 point의 개수가 적은 경우 size와 rotation에 대한 부정확함이 존재합니다. LiDAR와 거리가 먼 car의 경우 point가 10개보다 적은 경우가 있는데 이런 경우에도 rotation와 size에 대한 부정확한 예측 결과가 나옵니다.
Pedestrian and Cyclist Detection

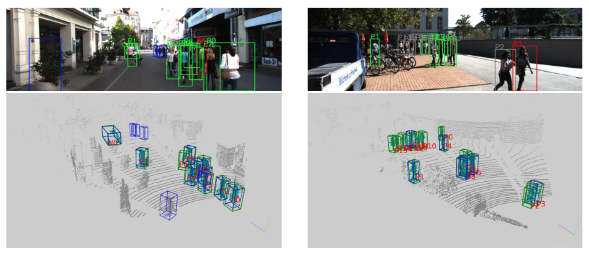
Car와는 달리 Pedestrian, Cyclist detection의 경우 더 많은 false positive와 false negative 결과가 나옵니다. 이미지 상에서 보면 정말 뜬금없는 곳에 bule box로 false positive 결과가 나온 것을 볼 수 있습니다.
이런 결과가 나온 이유는 image에서의 instance density가 car보다 높고 각 instance 마다 더 적은 point를 가지고 있기 때문에 다른 point나 noise와 혼동을 하기 쉽기 때문입니다.
또 다른 이유는 pedestrian과 cyclist는 적은 부피를 가지고 있기 때문에 CNN이 가지는 효과가 한계적으로 적용되는 것입니다.
하지만 이러한 2D detection 결과를 통해 관련 없는 point를 쉽게 filtering 하고 object location을 결정하는 데 사용이 가능하다는 것을 연구를 통해 알아냈다고 합니다.
Ablation Study
Sparse Convolution Performance

빠른 rule generation을 통해서 다른 convolution에 비해 매우 빠른 속도를 낼 수 있었습니다.
Different Angle Encodings

기존의 angle regression을 사용하는 것보다 더 높은 성능을 냈습니다.
Sampling Ground Truths for Faster Convergence

GT sampling을 통하여 Convergence 속도도 빨라졌고 AP도 더 높아졌습니다.