728x90
반응형
나의 정리
- residual learning을 통해 기존의 H(x)를 학습하는 것이 아닌 F(x)를 학습하여 optimize 하기가 더 쉽고 깊이가 늘어나도 높은 정확도를 얻을 수 있었다.
- optimize가 하기 쉬운이유는 F(x) = H(x) - x의 식이 되는데 결국 F(x)가 최소 값 0이 되는 곳을 찾는 것이라 H(x) = x로 목푯 값이 정해져 있어서 쉬워진다.
- 그저 더하는 연산이 추가된 것으로 파라미터 수가 변하지 않고 계산 복잡도 또한 낮다.
- Bottle neck → 차원수를 변경하여 parameter를 줄여 연산량을 줄이는 방식
- projection connection으로 차원수가 달라지면 차원수를 맞춰준다. (1x1 conv)
Abstract
- 네트워크가 깊어지면 깊어질수록 Train을 하는데 어려워 이를 해결하기 위해서 residual learning이라는 개념을 도입
- Residual network는 optimize하기가 더 쉽고 깊이가 늘어나도 정확도를 얻을 수 있다.
- 그럼에도 파라미터 수는 크게 변하지 않고 계산 복잡도 또한 낮다.
Introduction
- 네트워크의 깊이가 매우 중요한 것을 앞선 연구들을 통하여 알 수 있었다. (VGGNet에서 네트워크가 깊어질 수 록 높은 정확도를 볼 수 있었다.)
- depth가 중요해 지면서 layer를 쌓는 만큼 더 쉽게 네트워크를 학습시킬 수 있는지에 대한 의문이 생기기 시작, 특히 Vanishing / Exploding gradient 현상이 큰 방해 요소였다.
- SGD를 적용한 10개의 layer까진 normalization, BN과 같은 intermediate normalization layer를 사용하면 문제가 없었다.

- 하지만 깊은 네트워크의 경우 성능이 최고 수준에 도달할 때 degradation 문제가 발생했고 이는 그림에서 보다시피 train, test의 성능이 안 좋아지므로 Overfitting이 아니라 그저 layer의 수가 추가되었기 때문이다.
- 깊은 모델에서도 최적화를 진행하기 위한 방법으로 identity mapping과 shallower 모델로 학습한 layer를 사용한다. → shallow 모델에서의 training error보다 낮은 error를 깊은 네트워크 모델은 가지게 된다.
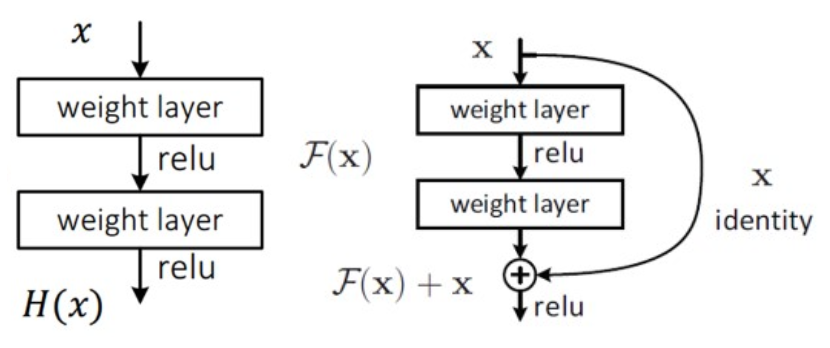
- 기존 네트워크들은 입력 x가 layer를 거친 H(x)를 출력하고 이는 입력값 x를 타겟 값 y로 mapping 하는 함수 H(x)를 최적화하는 것이 목적이다.
그러나 ResNet에서는 출력과 입력의 차인 H(x) - x를 최적화 하도록 목표를 수정한다.
→ 이는 출력과 입력의 차를 줄인다는 의미
⇒ x의 값은 도중에 바꾸지 못하는 입력 값이므로 F(x)가 0이 되는 것이 최적의 해이고 결국 0 = H(x) - x로 H(x) = x가 된다. - 즉, H(x)를 x로 mapping 하는 것이 학습의 목표가 된다.
- 이전에는 알지 못하는 최적의 값을 찾아가야 했는데 이제는 H(x) = x 라는 최적의 목푯 값이 사전에 preconditioning으로 제공되어 identity mapping인 F(x)가 학습이 더 쉬워진다.
identity mapping 이란?
identity function H(x) = x를 만족하도록 하는 것
- 장점
- 입력에서 출력으로 바로 연결되는 shortcut만 추가하면 되어 파라미터 수에 영향이 없고, 덧셈이 늘어나는 것 빼고는 연산량이 증가하지 않는다.
- 곱셈 연산이 덧셈 연산으로 바뀌어 forward, backward path가 단순해지고 gradient 소멸 문제를 해결 할 수 있었다.
- F(x)를 학습하면 되므로 최적화가 더 쉬워졌다.
Related Work
Residual Representations
- 벡터 양자화에 있어 residual vector를 인코딩하는 것이 original vector보다 훨씬 효과적이다.
- 벡터 양자화란? - 특징 벡터 X를 클래스 벡터 Y로 mapping 하는 것.
- 합리적인 문제 재구성과 전제 조건은 최적화를 더 간단하게 수행해준다.
Shortcut connection
- 다른 방식들과 달리 parameter가 전혀 추가되지 않으며 0으로 수렵하지 않기에 절대 닫힐 일이 없어 항상 모든 정보가 통과된다.
→ 지속적으로 residual function을 학습하는 것이 가능하다.
Deep Residual Learning
Residual Learning
- 실제로는 identity mapping이 최적일 가능성이 낮다. 하지만 pre-conditioning을 추가하는데 도움을 준다.
따라서 opitmal fucntion이 zero mapping보다 identity mapping에 더 가깝다면, solver가 identity mapping을 참조하여 작은 변화를 학습하는 것이 새로운 fucntion을 학습하는 것보다 더 쉽다고 주장한다.
Identity Mapping by Shortcuts
- 파라미터나 연산 복잡도를 추가하지 않는다.
- F + x 연산을 하기 위해선 x, F의 차원이 같아야하는데 이들이 서로 다를 경우 Linear projection인 Ws를 곱하여 차원을 같게 만들 수 있다. (차원 매칭 시켜줄 때만 사용)
Network Architectures
- Plain Network
- VGGNet에서 영감을 받아 3x3 conv filter 사용하고 2가지 규칙 기반 설계
- output feature map의 size가 같은 layer들은 모두 같은 수의 conv filter 사용
- output feature map의 size가 반으로 줄면 time complexity를 동일하게 유지하기 위해 필터 수를 2배로 늘린다.
- downsampling을 진행할 땐 pooling 대신 stride가 2인 conv filter를 사용한다.
모델 끝단에 Global Average Pooling을 사용한다. - VGGNet 보다 적은 필터와 복잡성을 가진다.
- VGGNet에서 영감을 받아 3x3 conv filter 사용하고 2가지 규칙 기반 설계
- Residual Network
- Residual Network는 Plain 모델에 기반하여 Shortcut connection을 추가하여 구성한다.
- 이때 input과 output의 차원이 다르다면,
- zero padding을 적용해 차원을 키워준다. projection shortcut을 사용한다. (1x1 convolution)
projection shortcut은 Ws를 곱하거나 1x1, stride 2 conv filter를 사용하여 차원을 맞춰주는 역할을 한다.
(추가) - Ws가 곧 conv filter이다. 왜냐하면 conv filter가 가중치이니까.
Implementation
- 짧은 쪽이 [256, 480] 사이가 되도록 random resize
- 224x224 random crop을 origin or horizontal flip image에서 진행하고 per-pixel mean을 빼준다.
- standard color augmentation 진행
- BN 적용하고 He 초기화 방법으로 가중치 초기화
- SGD, mini-batch: 256, LR: 0.1에서 시작하고 정체될 때 10씩 나눠준다.
- Weight decay: 0.0001, Momentum: 0.9
- 60x10^4 반복 수행, dropout 사용하지 않는다.
weight decay → overfitting을 방지해주는 역할을 해준다.
Experiments

ImageNet Classification
- Plain Network
- 18 layer보다 34 layer의 깊은 plain 모델에서 높은 validation error가 나타났다.
training/validation error를 비교한 결과 degradation 문제가 발생하였다. - Vanishing gradient 문제가 아니라고 판단하였고 exponentially low convergence rate를 가지기 때문이라고 추측하였다.
- 18 layer보다 34 layer의 깊은 plain 모델에서 높은 validation error가 나타났다.
- Residual Network
- 모든 shortcut은 identity mapping을 사용, 차원을 키우기 위해서는 zero-padding을 이용하여 파라미터 수는 증가하지 않았을 때 3가지 확인이 가능
- degradation 문제가 해결되어 depth가 증가해도 좋은 정확도를 얻을 수 있었다.
- residual learning이 extremely deep system에서 매우 효과적임을 알 수 있었다.
- ResNet은 더 빨리 수렴해 나간다.
- 모든 shortcut은 identity mapping을 사용, 차원을 키우기 위해서는 zero-padding을 이용하여 파라미터 수는 증가하지 않았을 때 3가지 확인이 가능
- Identity vs projection shortcut
- 3가지 옵션에 대해 비교
- zero padding shortcut을 사용한 경우 - dimension 키울 때 사용 모든 shortcut은 parameter가 변하지 않음
- projection shortcut을 사용한 경우 - dimension 키울 때 사용 다른 모든 shortcut은 identity하다.
- 모든 shortcut으로 projection shortcut 사용한 경우
- 3가지 옵션 모두 plain model 보다 좋은 성능, 1 <2 <3 순이었다.
- 1 <2는 zero-padded 차원이 residual learning을 수행하지 않기 때문 2 <3는 projcetion shortcut에 의해 파라미터가 추가되었기 때문 1, 2, 3 성능의 차이는 크지 않다.
- memory/time complexity와 model size를 줄이기 위해 3을 사용하지 않고 identity shortcut은 bottleneck 구조의 복잡성을 높이지 않는 데에 매우 중요하다.
- 3가지 옵션에 대해 비교
- Deeper Bottleneck Architectures
- ImageNet에 대한 학습 시 training time을 줄이기 위해 building block을 bottleneck design으로 수정하였다.
- identity shortcut이 projection shortcut으로 대체되면, shortcut이 2개의 high-dimensional 출력과 연결되어 time complexity와 model size가 2배로 늘어난다.
따라서 identity shortcut은 bottleneck design을 더 효율적인 모델로 만들어준다.
728x90
반응형