나의 정리
- 논문이 지적한 문제점: CNN, attention는 충분히 좋은 성능을 내지만 꼭 필수 적이지 않다. MLP만으로도 충분히 좋은 성능을 낼 수 있다.
해결 방안: Token mixing layer, Channel mixing layer 두 가지 MLP layer를 사용하여 모델을 구성했다. - 정말 모델 구성과 구현이 간단한 모델이고 이런 연구의 첫 주자인 것 같은데도 좋은 성능을 내서 정말 충격적인 논문이다.
Abstract
convolution과 attention은 모두 좋은 결과를 내지만 꼭 필수적이진 않다! 는 주장을 하는 논문 MLP-Mixer를 읽어보자.
MLP-Mixer는 간단하지만 경쟁력 있는 결과를 내는 모델을 소개한다.
2가지 종류의 layer를 가지고있다.
- image patch에 독립적으로 적용되는 mlp
→ per-location feature를 mixing 해주는 역할을 한다. (Channel mixing layer) - 모든 image patch를 거치도록 적용되는 mlp
→ spatial information을 mixing 해주는 역할을 한다. (Token mixing layer)
Introduction
Vision 분야에서 주로 사용되던 CNN의 대안으로 등장한 ViT는 hand-crafted visual feature와 모델의 inductive bias들을 제거하려는 연구이고 raw data의 학습에 의존하는 모델이다.
inductive bias란?
학습 시에는 보지 못했던 데이터에 대해서 정확한 예측을 하기 위해서 사용하는 추가적인 가정을 의미한다.
예를 들어 적당한 inductive bias를 학습했다면 어떤 data를 받더라도 local minimum에 빠지지 않고 올바른 방향으로 minimum을 찾게 된다.
CNN, attention을 사용하지 않고 간단한 mlp만으로도 경쟁력 있는 성능을 내는 모델을 소개.
input은 image를 작게 쪼갠 patch들을 하나의 FC layer를 거쳐서 projection 시킨 patch * channel의 matrix를 input으로 사용한다.
이때 만들어진 matrix를 token이라고 부른다.
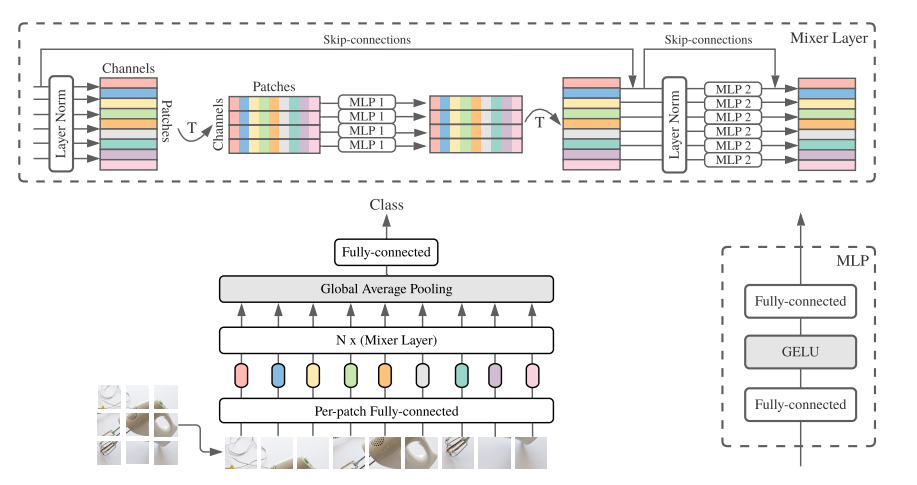
MLP-Mixer의 전체적인 구조이다.
위의 Abstract에서 언급한 두 가지 종류의 MLP를 좀 더 설명을 해보자면
- channel-mixing MLPs 서로 다른 channel끼리 token에 독립적으로 연산이 된다.
- token-mixing MLPs 다른 공간적인 정보끼리 channel에 독립적으로 연산이 된다.
MLP-Mixer를 CNN의 special case로 보는 것도 가능하다.
- channel-mixing은 1*1 conv로 볼 수 있다.
- token mixing은 filter size를 input spatial size와 동일하게 설정한 depth-wise conv로 볼 수 있기 때문이다.
- 하지만 CNN은 mlp보다 훨씬 복잡한 계산이다!
Mixer Architecture
현대 vision 딥러닝 모델들은 주로 아래와 같은 layer들로 구성되어 있다.
- 하나의 주어진 spatial location에서의 feature를 mix 해주는 layer
- 서로 다른 spatial location들 간의 feature를 mix해주는 layer
CNN의 경우에 N*N convolution과 pooling은 (2)를 수행하게 된다.
1*1 conv 같은 경우에는 (1)을 수행하게 된다.
larger kernel은 (1), (2)를 모두 수행한다.
attention 기반의 모델에서는 self-attention layer는 (1), (2)를 모두 수행한다.
MLP-Mixer는 이 두 operation을 명확하게 분리한다.
- non-overlapping image patch로 나누어서 hidden dimension C로 projection 시킨다.
→C가 channel dimension이 된다. - 차원에 대한 추가 설명을 해보면,
(H, W) 이미지를 (P, P) 사이즈의 patch로 쪼개게 되고 그 결과로 S = H*W/P^2 개의 patch를 얻는다.
p*p*3(RGB) 차원의 각 패치를 C dimension으로 projection 시킨 결과 S * C의 차원이 된다.
(patch 수 * Channel dimension)
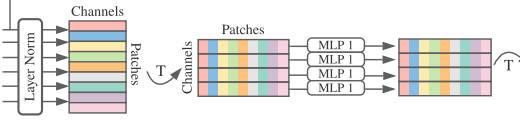
위 그림이 Token mixing layer이다.
위에서 설명한 token을 구해서 S*C 차원을 가지는 matrix를 layer norm을 먼저 거쳐준다.
거친 뒤 Transpose를 해주어 C*S 차원으로 바꿔준다.
바꿔준 뒤 MLP를 거쳐서 token 별로 feature를 섞어주게 된다.
이런 과정을 거치기 때문에 token mixing layer라고 부른다.

위 그림이 Channel mixing layer이다.
token mixing layer를 거친 feature를 다시 Transpose 해준 뒤 skip connection을 통해 원래 S * C matrix를 더해주고 layer norm을 거치게 된다.
norm을 해준 feature를 MLP를 거쳐서 channel 끼리 feature를 섞어주게 된다.
이런 과정을 거치기 때문에 channel mixing layer라고 부른다.

두 layer를 수식으로 나타내면 위와 같은 수식으로 나타낼 수 있다.
윗 줄의 수식이 token mixing layer, 그 밑이 channel mixing layer이다.
- MLP의 구성은 2개의 FC layer와 두 layer사이에 Activation 함수로 1개의 GELU로 구성이 된다.
- 마지막으론 Global Average Pooling을 통해 각 patch당 하나의 값을 뽑아내고 S*1의 마지막 fc classification head를 거쳐 class를 예측한다.
Experiments
- MLP-Mixer가 아직 정확도 측면에서 기존의 CNN, attention 기반의 모델들을 뛰어넘진 못하지만 계산 효율성은 좋은 편이다. ViT는 quadratic, MLP-Mixer는 linear의 관계를 가진다.
- ViT와 같이 대규모 데이터셋을 이용할수록 성능 향상이 있었다.
또 다른 흥미로운 실험이 있었다.

원본 이미지를 두 가지 방식으로 변환시킨 후 input으로 사용하여 train 해보는 실험
- Patch + pixel shuffling
- patch 순서를 랜덤 하게 섞고, patch 내부의 pixel들을 랜덤하게 섞기
- Global shuffling
- image 전체에서 pixel들을 랜덤하게 섞기
실험의 결과로 MLP-Mixer는 token mixing mlp을 통하여 patch의 순서에 무관 한하다는 결과를 얻었다.
따라서 patch 순서 변경, patch 내부 pixel 순서 변경에 대해서는 invariant 한 성질을 가진다.
하지만 global 하게 pixel을 섞는 경우에는 input을 만들 때 가정한 patch 내부의 pixel들의 그룹성을 위배하게 되므로 훈련이 더뎌진다.
일반적인 CNN은 인접 pixel들의 상대적 위치에 대해 강하게 의존하는 bias를 가지고 있어서 두 변환 모두 큰 성능 저하를 겪는다.
Conclusion
MLP 만 사용하여서 매우 단순하고 계산 복잡도에서 이득을 가지지만 성능 또한 경쟁력 있는 성능을 얻을 수 있는 model이다.
mlp만으로 sota에 근접한 성능을 낸다는 것이 정말 인상적인 논문이었다.