나의 정리
- 논문이 지적한 문제점: 기존의 anchor 기반의 detector들은 사전 정의된 anchor를 사용하므로 섬세하고 많은 parameter tuning이 있어야 하고 계산량이 많이 들어가게 된다. 또한 Fully convolution이 아니기 때문에 다양하게 활용할 수 없다.
- 해결 방안: anchor-free 모델을 고안하였다. 이를 통해 계산량을 줄였고 design을 좀 더 간단하게 할 수 있게 하였다. 또한 x, y가 object의 bbox 안에만 있고 class가 같다면 positive sample로 사용하여서 기존의 anchor 기반의 모델들보다 더 많은 양의 positive sample을 사용하는 장점을 통해 성능 개선을 하였다. 두 객체가 겹쳐져 있어서 어떤 객체로 regression 할지 애매한 문제인 ambiguous 문제를 multi-level prediction을 이용해 개선했다. object의 중심에서 먼 위치에서 predict된 low-quality bbox에 대해선 “center-ness”라는 term을 추가하여 개선하였다.
Abstract
논문 제목과 같이 one-stage의 Fully Convolutional Detector를 고안하였다. 기존 object detection의 방법에서는 대부분 사전에 정의된 anchor를 사용했지만 이 논문은 anchor free 방식으로 anchor를 사용하지 않아 anchor의 hyper-parameter를 튜닝해주지 않아도 되고 anchor를 사용할 때 필요한 복잡한 계산 과정들을 거치지 않아도 된다. 간단하고 유연한 detection framework를 만들었다고 한다.
Introduction
현재 detector는 대부분 사전 정의된 anchor에 의존을 해왔고 detector의 성공은 anchor의 사용이 핵심이라고 믿어져 왔다. 하지만 anchor box 사용의 단점들이 존재한다.
- detection 성능 자체가 anchor box의 size, aspect ratio, anchor의 개수에 의해서 매우 민감해진다. 이러한 hyper-parameter를 잘 튜닝해야 한다는 점이 있다.
- 잘 design 한 anchor를 사용하더라도 anchor의 scale, aspect ratio는 이미 정해져 있기 때문에 특히 작은 물체의 모양이 크게 변하게 된다면 어려움을 겪게 된다. 또한 만약 다른 detection task에서 동작할 때 object들은 또 서로 다른 size, ratio를 가지기 때문에 detector의 generalization을 방해하게 된다.
- 높은 recall을 얻기 위해서, anchor를 사용하는 detector들은 input image에 엄청나게 많은 anchor를 사용하게 된다. 예를 들어 FPN에서는 180K 개의 anchor box를 사용하였다. 하지만 이렇게 많은 anchor box들은 거의 대부분 negative sample이 된다. (image 상에서 대부분의 공간들은 background이기 때문!) 따라서 이는 positive sample과 negative sample 간의 imbalance를 야기하게 된다.
- anchor box를 사용하게 된다면 ground truth와 IOU score를 계산해야 하는 등 복잡한 계산을 해야 한다.
기존의 Object detection들은 anchor의 사용으로 fully convolution으로 설계하기가 어려웠다. per-pixel prediction으로 object detection이 가능할까란 질문을 논문 저자가 스스로 해봤고 그 대답은 가능하다고 생각했다! 더 간단한 FCN based detector가 anchor 방식보다 오히려 더 좋은 성능을 냈다고 한다.

FCN-based framework는 feature map에서 각각의 spatial 위치의 4D vector (l, t, r, b), class 총 다섯 개를 예측해 낸다. 4D vector는 bbox의 네 면과 object의 위치까지의 offset을 의미한다. (figure 1 왼쪽 그림 참조)
이와 유사한 연구인 DenseBox는 다른 크기의 bbox를 다루기 위해서 training data를 고정된 크기로 crop, resize를 진행하게 된다. 또한 image pyramid를 사용해서 detection을 진행하기 때문에 모든 convolution을 한 번만 거친다는 것에 위배가 된다. 게다가 이 방식은 scene text detection, face detection과 같은 특별한 domain에서 사용이 되고 figure 1의 오른쪽 그림과 같이 object끼리 많이 겹친 영역에 대해서는 어떤 영역으로 regress를 해야 할지 모호한 점이 있어 잘 동작하지 않을 수 있다.
이 부분에 대해서 자세히 살펴보고, FPN을 사용하면 앞서 언급한 모호함을 제거할 수 있다는 것을 보여주고 결과적으론 전통적인 anchor base 방식의 성능과 비슷하게 나온다는 것을 보여준다. 게다가 object의 중심과 멀리 떨어진 위치에서 많은 양의 low-quality bbox를 예측할 수 있는 걸 발견하여, bbox 중심에 대한 pixel의 편차를 예측하는 “center-ness”라는 개념을 도입한다.
FCOS의 장점을 요약해보자면 아래와 같다.
- FCN으로 해결이 가능한 semantic segmentation과 같은 다른 task들과 합쳐서 다시 사용할 수 있다.
- anchor, proposal을 사용하지 않아 튜닝해야 할 parameter들이 줄어들어 좀 더 단순하게 학습이 가능하다.
- IOU 계산과 GT box와 anchor box의 matching을 하지 않아도 되므로 메모리가 적게 들고 빠른 학습이 가능하다.
- one-stage detector에서 SOTA 성능을 냈다. FCOS는 RPN을 사용해서 two-stage로도 사용이 가능한데 이때는 기존의 anchor 방식들보다 더 높은 성능을 낼 수 있었다고 한다!
- FCOS로 최소한의 수정으로 다른 vision task를 해결할 수 있다.
Related Work
Anchor-based Detectors
anchor 기반 detector는 Faster R-CNN과 같은 곳에서 사용된 전통적인 sliding-window, proposal 기반의 idea로 시작한다. Anchor box는 BBox 위치 예측을 개선시키기 위해서 extra offset regression과 함께 positive, negative patch로 분류시키는 역할을 한다. Anchor box는 CNN의 feature map을 사용하고 반복적인 feature 계산을 하지 않게 하여 속도를 매우 빠르게 만들었다.
그러나 anchor box는 위에서 언급했듯 너무 많은 hyper-parameter를 사용하고 정교하게 튜닝을 해야 좋은 성능 향상이 가능하다는 단점이 있다. 또한 label을 지정하는 hyper-parameter도 지정해줘야 해 design이 복잡하고 계산량도 복잡하다.
Anchor-free Detectors
YOLO는 object의 중심과 가까운 점에서 bbox를 예측하게 된다. 그러나 YOLO v1은 너무 낮은 recall을 갖는 문제점이 있어서 YOLO v2에서부턴 anchor box를 사용하게 된다. FCOS는 GT box의 모든 점들을 이용해 bbox를 예측하고 low-quality bbox에 대해서는 “center-ness”를 이용해서 처리하게 된다.
CornerNet은 게시물 참조 - https://talktato.tistory.com/19
[논문 리뷰] CornerNet: Detecting Objects as Paired Keypoints (2018)
나의 정리 논문이 지적한 문제점: Anchor를 사용하는 one-stage 방식이 비효율 적이고 학습에 방해가 되는 요소들이 있다. 해결 방안: Anchor가 아닌 Corner를 이용하여 object detection을 수행하였다. anchor
talktato.tistory.com
Method
FCOS는 먼저 per-pixel prediction으로 object detection 문제를 재정의하고, multi-level prediction을 통하여 recall을 개선하고 겹쳐진 bbox에 대한 ambiguity를 해결하였다. 마지막으로 “center-ness”를 이용해 low-quality bbox를 극복하고 성능을 크게 높였다.
1. Fully Convolutional One-stage Object Detector
backbone을 통해서 나온 i layer에서의 feature map을 $F_i \in R^{H\times W \times C}$ 라고 정의하고, GT BBox를 $B_i = (x^{(i)}_0, y^{(i)}_0, x^{(i)}_1, y^{(i)}_1, c^{(i)})$ 라고 정의한다. $(x_0^{(i)}, y_0^{(i)})$ 는 left-top을 의미하고 $(x_1^{(i)}, y_1^{(i)})$ 는 right-bottom을 의미하고 c는 class를 의미한다.
Feature map $F_i$ 위의 (x, y)는 다시 input image 상의 receptive field의 center인 $([\frac{s}{2}] + xs, \frac{s}{2} + ys])$ 로 표현이 가능하다. 이때 s는 total stride를 의미한다.
FCOS는 training sample를 이용해서 바로 BBox를 regression 한다. x, y의 위치가 GT BBox에 속하고 class가 같다면 positive sample로 간주하여 사용을 하게 된다. 만약 그렇지 않다면 negative sample로 사용을 하고 class가 0이라면 background로 간주를 하게 된다.
4D vector $t^* = (l^, t^, r^, b^)$ 를 사용해 위치 정보의 regression target으로 설정하게 된다. 이때 각각의 의미는 앞서 언급했듯 bbox의 네 변 사이와의 거리를 의미한다. 만약 (x, y)가 BBox에 속해있다면 regression target은 아래와 같이 계산할 수 있다.
$l^* = x - x_0^{(i)}, t^* = y - y_0^{(i)}, r^* = x_1^{(i)} - x, b^* = y_1^{(i)} - y$
기존의 anchor 기반의 detector들은 IOU를 통하여 높은 것에 대해서만 positive sample로 사용을 하게 된다. 이에 반해서 FCOS는 x, y가 GT BBox 안에만 속한다면 regression target을 설정하여 positive sample로 사용해 더 많은 positive sample을 사용이 가능하게 되어 더 높은 성능을 낼 수 있었다고 한다.
Network Outputs
training target에 해당하는 신경망의 마지막 layer는 classification label의 80D vector p와 4D vector t = (l, t, r, b)인 bbox 좌표를 예측하게 된다. multi-class classifier를 학습하는 대신 C binary classifier를 학습한다. backbone 신경망의 feature map 뒤에 4개의 Conv layer를 추가한다. regression target은 항상 양의 값 이므로 exp(x)를 사용해 임의의 실수를 regression branch 맨 위에 있는 (0, inf)에 매핑을 시킨다.
FCOS는 location 당 9개의 anchor box가 있는 detector보다 output 변수가 9배 적다.
Loss Function
$L(\{p_{x,y}\}, \{t_{x,y}\}) = \frac{1}{N_{pos}}\sum_{x,y}L_{cls}(p_{x,y}, c^{x,y}) + \frac{\lambda}{N{pos}}\sum_{x,y}1_{\{c^{x,y}>0\}}L{reg}(t_{x,y}, t^*_{x, y}),$
$L_{cls}$ 은 focal loss를 사용하고 $L_{reg}$ 은 UnitBox의 IOU loss를 사용한다. $N_{pos}$ 는 positive smaple의 개수이고 $\lambda$ 는 $L_{reg}$ 에 대한 balance weight로 1로 사용한다. $1_{\{c^_i > 0\}}$ 은 $c^_i$ 이 0보다 클 땐 1이고 0보다 작을 땐 0이 된다.
2. Multi-level Prediction with FPN for FCOS
FCOS는 multi-level prediction과 FPN을 이용해서 두 가지 문제를 해결할 수 있다.
첫째로는 large stride(e.g. 16x)로 인해서 마지막 feature map은 낮은 Best Possible Recall(BPR)을 야기할 수 있다. anchor 기반의 경우엔 positive box를 구하기 위한 IOU score 값을 낮춰서 보상을 한다. 하지만 FCOS는 large stride로 인해 마지막 feature map에서 위치가 encode 되는 곳이 없는 object를 recall 할 수 없기 때문에 anchor 기반의 detector보다 더 낮은 BPR을 가진다고 생각할 수 있다.
하지만 FCN-based FCOS는 large stride에서도 좋은 BPR을 가지는 것을 실증적으로 입증했다고 한다. 실제적으론 BPR은 FCOS의 문제가 되지 않으며 multi-level FPN prediction의 경우 BPR이 더 개선될 수 있다고 한다.
두 번째로는 GT box가 겹쳐짐으로써 어떤 bbox로 regression을 해야 하는지 모호함을 가진다는 점이다. 이는 FCN based detector에서 성능을 많이 떨어뜨리게 되는데, 이는 multi-level prediction을 통하여 해결하여 좋은 성능을 낼 수 있다고 한다.

FPN을 사용해서 각기 다른 크기를 가지는 5개 level의 feature map을 사용한다. $\{P_3, P_4, P_5, P_6, P_7, \}$ 로 정의되고 $P_3, P_4, P_5$ 는 각각 backbone CNN의 feature map $C_3, C_4, C_5$ 로 생성이 되고 그 이후론 top-down connection으로 $1 \times 1$ convolutional layer를 거치게 된다. $P_6, P_7$ 은 각각 $P_5, P_6$ 에 stride 2를 가지는 convolutional layer를 추가해서 만들게 된다. 결과적으로 8($P_3$ 부터 차례로), 16, 32, 64, 128의 stride를 가지게 된다.
크기가 다른 anchor box를 다른 feature level에 할당하는 방식과는 달리 FCOS는 각 level에 대한 BBOX의 regression 범위를 직접 제한한다. 앞서 언급했던 regression target($l^, t^, r^, b^)$ 을 모든 feature level의 각각의 위치에서 계산을 한다. 그다음 계산한 위치가 $max(l^, t^, r^, b^) > m_i$ 거나 $max(l^, t^, r^, b^) < m_{i-1}$ 이면 negative sample로 간주해 더 이상 계산을 하지 않아도 된다. 여기서 $m_i$ 가 의미하는 바는 feature level i가 regression 해야 하는 최대 거리를 의미한다. $m_1$ 부터 차례로 0, 64, 128, 256, 512, inf 값을 가지게 된다. (i는 1~7까지의 값을 가진다.)
크기가 다른 객체는 다른 feature level에 할당되고 대부분의 overlap은 크기가 상당히 다른 객체 간에서 발생한다.(앞선 figure 1의 오른쪽 그림 참고) multi-level prediction을 사용해도 위치가 여전히 2개 이상의 GT box에 할당된다면 간단하게 minimal area의 GT Box를 선택하게 된다.
서로 다른 feature level 간에 head를 공유해 parameter를 효율적으로 만들고 성능도 크게 개선을 한다. 하지만 다른 크기의 범위를 regression 하기 위해선 다른 feature level에 동일한 head를 사용하는 것은 좋지 못하다. ($P_3$ 에서는 [0, 64], $P_4$ 에서는 [64, 128]의 크기 범위를 가진다.)
따라서 standard exp(x)를 사용하지 않고 $exp(s_ix)$ (학습 가능한 scalar $s_i$ 를 사용)을 사용하여 feature level $P_i$ 에 대한 exponential function의 base를 자동으로 조정해서 성능을 개선하였다.
3. Center-ness for FCOS
multi-level prediction을 사용한 후에도 anchor 기반 detector와 성능 차이가 있었던 이유는 객체의 중심에서 멀리 떨어진 곳에 의해 생성된 low-quality predicted bbox 때문이라고 생각해서 hyper-parameter를 사용하지 않고 해결이 가능한 “center-ness”를 도입하였다.
center-ness는 location에서 해당 location이 속한 object의 중심까지의 거리를 정규화된 값으로 나타낸다. location을 위한 regression target $l^, t^, r^, b^$ 가 주어지면 center-ness target은 아래와 같이 주어진다.
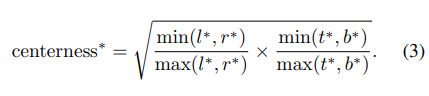
center-ness의 값은 0~1 사이의 값이고, Binary Cross Entropy(BCE) loss로 학습을 한다. 최종 score는 center-ness와 해당 classification score를 곱하여 계산이 된다. 이를 통해서 object의 중심과 멀리 떨어져 있는 bbox의 score를 낮출 수 있게 된다. →center-ness가 down-weight의 역할을 해준다.
결과적으로 이러한 low-quality bbox는 최종 NMS에 의해 높은 확률로 필터링되기 때문에 성능이 크게 향상될 수 있다.
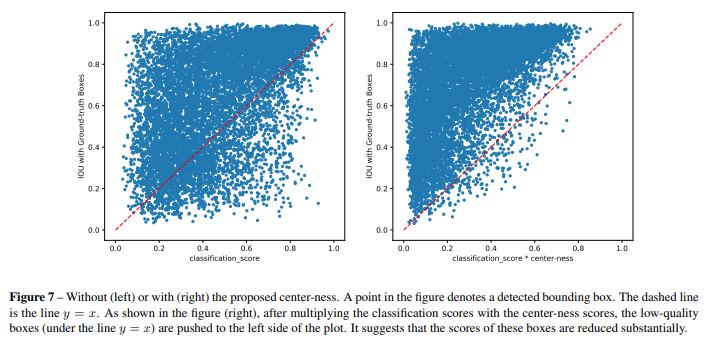
위의 그림 왼쪽을 보면 낮은 품질의 bbox(low-quality predicted bbox)가 많이 존재하게 된다. 하지만 center-ness score와 classification score를 곱한 값을 이용하면 낮은 품질의 bbox를 많이 줄일 수 있어서 성능 개선을 얻을 수 있다는 것을 알 수 있다.
center-ness의 대안으로는 하나의 추가적인 hyper-parameter를 추가해 GT bbox의 중앙 부분만 positive sample로 사용할 수 있다. center-ness와 대안 두 개를 조합하여 사용했을 때 더 높은 성능 gain이 있었다.
Experiments

성능표
Ablation Study
Multi-level Prediction with FPN

low-quality match를 이용하면 anchor base의 detector에 비슷한 BPR을 얻을 수 있다.

FPN을 사용하지 않으면 23.16%의 많은 ambiguous sample이 존재한다. FPN을 사용하는 경우 7%대까지 줄일 수 있다.

center-ness는 AP를 매우 크게 높인 것을 볼 수 있다.

다른 SOTA 모델들과의 비교표