나의 정리
- 논문이 지적한 문제점
기존의 Cartesian coordinate의 BEV 상에서 object detection은 ego car 기준의 환경을 인식하는데 자연스럽지 못한 방식입니다. 또한 Polar coordinate에서 convolution은 input structure shape이 맞지 않아 적용이 어렵습니다. - 해결 방안
Polar coordinate의 BEV feature를 생성하고 해당 feature를 Transformer를 사용하여 detection을 진행하는 모델을 제안합니다.
Abstract
지금까지 3D object detection을 진행할 때 주로 Cartesian coordinate $(x, y)$ 상에서 진행이 되어 왔습니다.
하지만 ego car를 기준으로 Cartesian coordinate을 가져가는 것은 자연스러운 방법이 아니라고 주장합니다. 저자들은 ego car 기준의 polar coordinate $(r, \theta)$ 상에서 3D object detection을 진행해야 한다고 주장합니다.

또한 기존에도 LiDAR Detection에서 Polar coordinate을 사용하여 제안한 모델이 존재하였습니다. 하지만 이때는 convolution을 사용하였기 때문에 Rectangular grid 구조에 대한 한계가 존재하였습니다. 따라서 input structure shape에 제한이 없는 Trasformer 구조를 사용하는 model을 제안합니다.

기존 연구들에서는 Cartesian coordinate의 BEV를 생성하여 detection을 진행했지만 이 논문에서는 이미지 만을 가지고 Polar coordinate의 BEV를 생성하기 위해 Polar Transformer를 제안했습니다.
Introduction
Polar Transformer는 image에 해당하는 polar ray를 cross-attention으로 학습하고 BEV Polar representation으로 feature를 생성하는 방식으로 진행합니다.
PolarFormer의 contribution은 아래와 같습니다.
- Polar coordinate system에서 multi-camera 3D object detection을 진행하는 Polar Transformer를 제안하였습니다.
- Polar Transformer의 key design은 irregular Polar grid를 처리하기 위한 cross-attention 기반의 decoder, object scale varation을 해결하기 위한 multi-scale polar representation 학습 방법입니다.
- nuScenes dataset으로 기존 방법보다 높은 성능을 달성했습니다.
Method
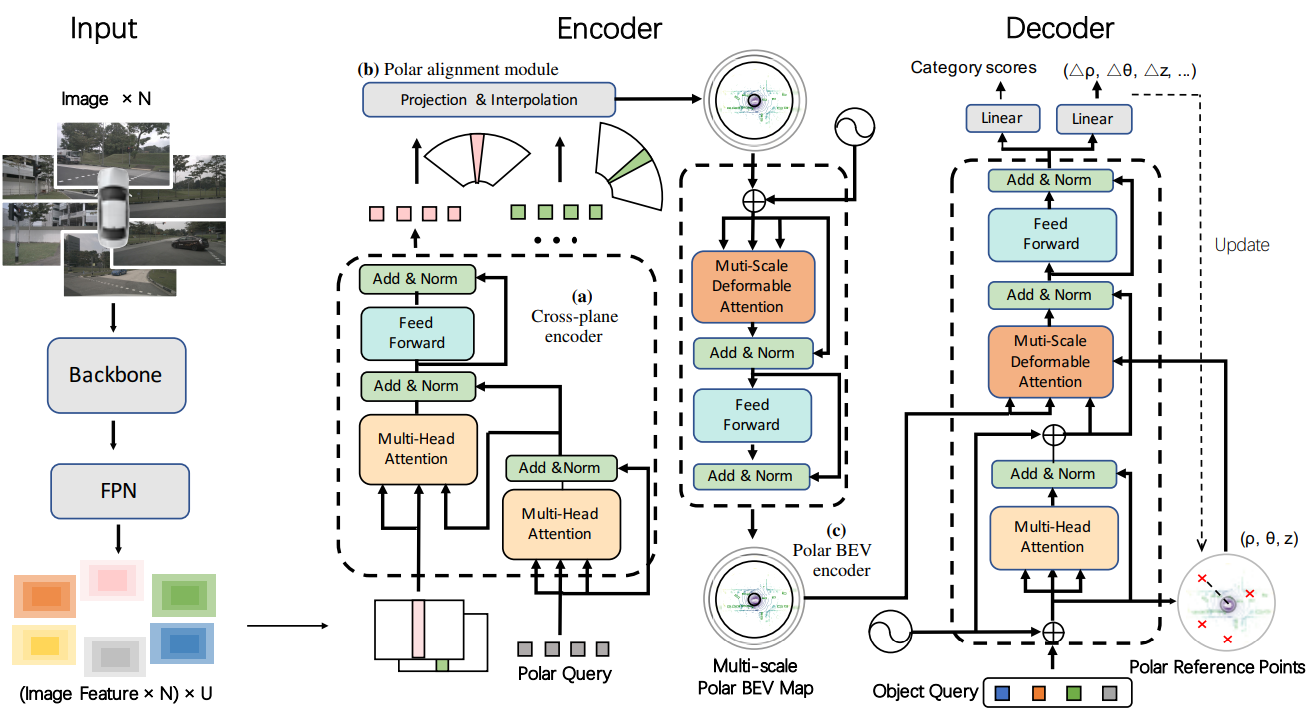
전체 모델 구조는 위와 같습니다. 모델 파이프 라인을 간단히 설명하면 먼저 multi-camera image를 backbone network를 사용해 feature를 생성합니다. 해당 feature를 cross-plane encoder를 사용해 BEV feature를 생성하고 이후 Polar alignment module로 해당하는 위치에 align 시켜 polar BEV feature를 생성합니다. Polar BEV encoder를 사용하여 multi-scale Polar BEV map을 생성한 뒤 Decoder의 object query를 사용해 3D object detection을 진행합니다.
크게 4가지 모듈로 구성되어 있고 아래 순서대로 각 모듈을 설명하겠습니다.
- Cross-plane Encoder
- Polar Alignment module (across multiple cameras)
- Polar BEV Encoder
- Polar BEV Decoder
Cross-plane encoder
FPN으로 추출한 image feature와 Polar query를 cross-attention을 통해 BEV 상의 3D feature를 생성하는 역할을 합니다.

polar query를 생성하고 polar query와 image feature를 cross-attention을 통해 3D feature를 생성합니다.


camera coordinate의 $x^{(C)}$를 intrinsic parameter로 image coordinate $x^{(I)}$로 바꿔준 뒤 polar coordinate (range $\rho^{(P)}$, azimuth $\phi^{(P)}$)로 변경해줍니다.
single image로 depth estimation시에 ill-posed problem이 존재하므로 BEVFormer와 같이 attention mechanism으로 image pixel과 polar를 association 해줍니다.

Multi-head attention을 사용하여 polar ray feature를 생성합니다. 여기서 query는 polar ray query$\dot{p}{n,u,w}$, key와 value는 image column feature $f{n,u,w}$로 사용합니다.

cross-attention을 통해서 얻은 polar ray query를 azimuth 방향으로 stack 하여 BEV Polar feature map을 생성합니다.
Polar Alignment across multiple cameras
서로 다른 camera coordinate 상의 polar ray를 공통된 world coordinate 상의 polar ray로 맞춰주는 역할을 합니다.

input으로 이전 cross-plane encoder에서 생성한 polar feature map과 camera calibration matrix를 사용하여 BEV Polar map을 생성합니다.


먼저 원기둥 좌표계에서 uniform 하게 3D point(들을 생성합니다. 그다음 해당 point를 image로 projection 시켜서 어떤 n 번째 image 위로 projection 되는지 판단합니다. 이런 방법으로 polar ray의 index를 찾습니다.
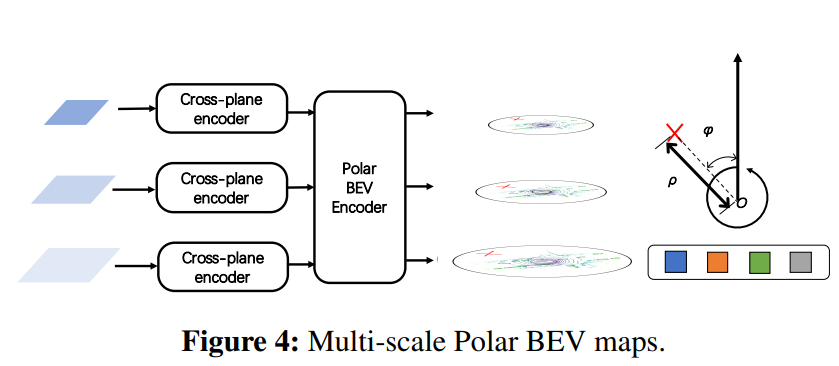
Polar BEV Encoder
Polar coordinate 상에서 object scale variance 문제를 해결하기 위해서 multi-scale feature map을 사용합니다. 또한 multi-scale Deformable Attention을 통해 polar 좌표계 상에서 주변 pixel, multi-scale 사이의 interaction을 반영합니다.

$z_q$: query feature $x_q$: query의 좌표, $G_u$: multi-scale polar feature map, $A_{muqk}$: normalized attention weight, m: attention head, u: scale, k: sampling offset이고 $\zeta_u$는 sampling offset을 생성하고 u 번째 feature scale에 맞춰서 rescale을 진행하는 함수입니다.
위의 방식으로 multi-scale Polar BEV feature map을 생성합니다.
Polar BEV Decoder

Polar coordinate 사에서 3D bounding box를 예측합니다. Transformer decoder에서 주로 사용되는 object query를 사용하여 object를 찾아냅니다. Multi-scale Deformable Attention으로 object query를 학습시키고 최종적으로 object query를 사용해 classification과 regression을 진행합니다.
Experiments

BEVFormer보다 높은 성능을 냈습니다.

(a)를 보면 feature와 prediction을 모두 polar로 하였을 때 성능이 가장 높았습니다.
(b)에선 position encoding 시에 learnable 하게 진행하는 것보다 fixed sine PE를 사용한 것이 가장 좋았습니다. learnable 하게 PE를 진행하는 것보다 그냥 고정된 sine PE를 하는 게 더 좋은 것이 신기했습니다.
(c)에선 multi-scale의 효과를 볼 수 있고
(d)에선 polar resolution에 따른 성능 변화를 볼 수 있습니다.