나의 정리
- 논문이 지적한 문제점
adverse weather에 대한 robust 3D object detection을 위해선 환경의 영향을 덜 받는 radar sensor의 사용이 필요하고 image와 효과적인 fusion 방식을 통해서 좋은 성능을 내는 것이 필요합니다. - 해결 방안
joint 3D-space로 camera feature와 radar feature를 projection 시켜 하나의 major sensor를 두지 않아 하나의 sensor가 fail 하더라도 robust하게 3D object detection을 가능하게 하였습니다. camera의 depth estimation 성능을 높이기 위해서 radar feature를 cross attention을 사용해 depth를 refine 해줍니다. (ray-constrained cross-attention) 또한 학습 시에 sensor 하나의 feature를 0으로 만들어서 학습을 진행하는 sensor dropout 방식을 사용하여 robust한 학습을 진행 할 수 있게 해줍니다.
Abstract
안전한 자율 주행을 위한 3D object detection은 Robust 해야 합니다. Camera와 Radar는 서로 다른 환경에서 상호 보완적으로 동작할 수 있습니다. 따라서 이 논문에서는 camera와 radar data를 fusion 하여 robust 한 3D object detector를 제안합니다.
Camera와 Radar를 fusion하는 것은 어려운 점이 존재합니다. camera의 경우 depth 정보가 존재하지 않고 radar의 경우 elevation 정보가 존재하지 않습니다. 이를 joint 3D space에서 fusion 함으로 써 서로에게 부족한 부분들을 채워주는 CramNet을 제안합니다.
- Radar data의 range 정보를 활용하여 camera의 depth estimation 성능을 높입니다.
- ray-contrained cross-attention mechanism
- 하나의 sensor가 fail하는 경우에 대해서 더 ruboust한 학습을 하기 위한 학습 방법을 제시합니다.
- sensor dropout
RADIATE dataset으로 Camera-Radar fusion method를 평가하고 monocular 3D object detection 성능은 Waymo에서 평가했습니다.
Introduction

RADIATE dataset에서 제공하는 radar data의 경우에 기존의 nuScene에서 제공하던 Point cloud 형식의 data가 아닌 radio frequency (RF) image로 주어집니다.
radar image는 BEV 상에서 다양한 noise를 가지고 주변 환경에 대한 정보를 제공합니다. camera image의 경우엔 perspective view 상의 정보를 제공합니다.
서로 다른 view를 가지고 있기 때문에 geometry 정보를 통하여 서로의 위치를 matching 해주어야 합니다. fusion을 위해 matching을 하는 세 가지 방법이 존재합니다.
- Perspective view
만약 depth 정보를 모른다면 ray를 쏴서 해당 point와 matching을 하는 방식도 존재합니다.
perspective view에서의 depth estimation을 통해 depth를 추정하여 3D location으로 projection을 시킨 뒤 해당 하는 위치의 수직 방향의 가장 가까운 radar point를 matching 하는 방식입니다. - Bird’s-eye view
radar image의 BEV에서 elevation을 바로 추정하는 방법은 매우 어렵습니다. 하나 가능한 방법은 map 정보를 이용하여 elevation 정보로 활용하는 방법입니다. - Cross-view matching
이 방식을 활용하면 uncertainty를 고려할 수 있다고 합니다. joint 3D-space에서 matching을 하는 방식입니다. camera에서 depth estimation, radar image에서 map 정보를 활용해 두 image pixel을 3D point cloud 상으로 변환하고 두 point cloud 끼리 matching을 진행하는 방식입니다.
하나의 major sensor를 정하고 fusion하는 방식은 major sensor fail의 경우 매우 큰 성능 저하가 존재합니다.
따라서 CramNet에서는 3번 cross-view matching을 이용해서 joint 3D-space 상에서 point cloud 형식으로 fusion을 진행합니다.
Contribution을 정리하면 아래와 같습니다.
- sensor fail이 일어나도 robust한 3D object detection이 가능한 구조를 제안하였습니다.
- fusion 방식이 camera only, radar only를 뛰어넘는 성능을 가져 data를 효율적으로 사용하는 것을 증명하였습니다.
- ray-constrained cross-attention을 통해서 radar의 range로 image depth estimation 성능을 개선하였습니다.
- Sensor dropout으로 robustness를 높였습니다.
- RADIATE dataset으로 fusion 방식에서 SOTA 성능과 waymo dataset에서 camera-only 방식에서 경쟁력 있는 성능을 냈습니다.
Method

CramNet의 전체적인 구조입니다. 구조를 먼저 살펴보면 크게 3가지 단계로 진행됩니다.
1. 2D foreground segmentation
camera, radar image를 각각 U-Net을 사용하여 segmentation을 진행합니다. 이때 camera는 depth estimation을 한번 진행합니다. 여기서 생성된 초기 depth 값과 radar feature를 사용하여 cross attention을 통해서 좀 더 정확한 depth estimation을 진행합니다. (ray-constrained cross-attention)
→ depth estimation GT는 LiDAR point cloud를 projection 시켜 사용합니다.
이때 Segmentation GT는 3D bounding box를 2D로 projection 하여 사용하였고 loss는 pixel-wise focal loss를 사용하였습니다.

2. 2D to 3D projection and point cloud fusion
두 feature에서 foreground feature에 대해서 point cloud로 변환하여 modality coding을 추가한 뒤 joint 3D-space로 projection 시킵니다.
Image는 depth estimation을 통해 얻은 값으로 projection을 진행하고 Radar의 경우 sensor의 높이를 elevation으로 사용하여 BEV → 3D로 변환을 합니다. 만약 언덕과 같은 경우에는 map 정보를 더 해주어서 사용했다고 합니다.
3. 3D foreground point cloud detection
foreground point cloud에 dynamic voxelization을 적용하여 sparse voxel feature를 생성합니다. 그 이후 sparse convolution network를 이용하여 3D box regression을 진행합니다.
anchor free 기반으로 CenterNet과 같이 heatmap을 예측합니다. (focal loss 사용)
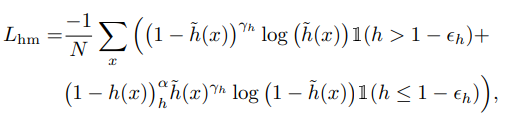
3D bbox regression에 사용된 loss는 아래와 같습니다.

Smooth L1 loss는 3D box regression loss, bin loss는 heading을 위한 loss, IoU loss는 additional loss로 성능 개선을 위해 추가하였습니다.
아래는 CramNet의 최종 Loss 식입니다.

Ray-Constrained Cross-Attention

radar의 range 정보를 활용하여 camera의 depth를 refine 시켜 주는 과정입니다. Radar feature와 camera feature 간의 geometric ambiguity를 해결하기 위해 활용한 방법이라고 합니다.

먼저 초기 depth estimation$(\tilde{d}_i)$을 중심으로 일정 거리$(\epsilon)$를 두고 s 개의 point를 sampling 합니다. → 위의 그림은 s=2 총 5개의 point를 sampling 하여 3D loaction의 집합 $\tilde{M}(\tilde{d}_i\pm\epsilon\times{k})\in\R^{(2s+1)\times{3}}$ 을 구합니다.
Sampling 된 location에서 가장 가까운 radar feature를 sampling 합니다.
→ radar feature 집합 $\psi_{Ri}\in\R^{(2s+1)\times{d}}$
위와 동일하게 가까운 camera feature를 sampling 합니다.
→ camera feature 집합 $\psi_{Ci}\in\R^{(2s+1)\times{d}}$

위에서 구한 location, feature 집합들을 사용하여 cross-attention을 진행합니다. 이때 Key는 radar 2D feature, Queue는 Camera 2D feature, Value는 Camera 3D point cloud입니다.
Sensor Dropout
학습 과정에서 하나의 sensor feature를 사용하지 않고 학습을 진행하는 학습 방법을 제시합니다.
이를 통해서 sensor fail 시에도 detection 성능을 크게 하락시키지 않는 robustness를 얻을 수 있습니다.

$r1, r2$: uniform random number [0, 1], $p_{drop}$: dropout 확률
위의 식으로 간단한 방식으로 진행됩니다.
$r1$으로 dropout을 할지 말지 판단하고 $r2$의 확률에 따라서 camera나 radar feature 중 하나의 feature를 0으로 하여 학습이 진행됩니다.
→ 이때 두 feature가 모두 0이 되는 경우는 없습니다!
또한 Dropout 하는 경우 feature를 0으로 만들어서 진행을 하기 때문에 해당 위치의 point cloud는 남아있게 됩니다.
만약 camera feature를 dropout 하는 경우 camera point cloud를 생성할 때 modality coding을 할 때 feature를 0으로 만들고 coding을 하고 joint 3D-space로 projection 하여 feature가 0인 point cloud로써 활용합니다.
Experiments

Camera-only, Radar-only로 학습한 경우보다 fusion을 한 경우 훨씬 더 높은 성능을 내는 것을 볼 수 있습니다.

cross-attention과 dropout 모두 성능 gain이 있었던 것을 볼 수 있고 Radar image를 사용할 때 intensity threshold를 사용하지 않고 그냥 원본을 사용하였을 때 가장 좋은 성능을 냈습니다.
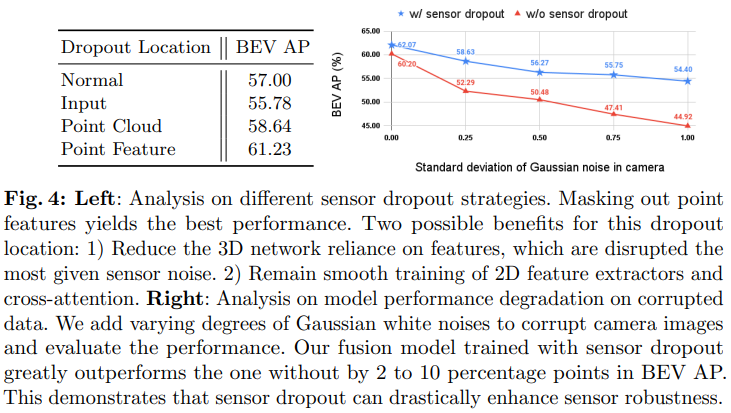
Dropout 하는 위치에 대한 실험인데 feature를 0으로 하는 것이 가장 좋은 성능을 냈습니다. point cloud가 그래도 존재해서 그 부분에 대한 도움을 받을 수 있었던 것이 성능 차이의 큰 요인인 것 같습니다. 또한 sensor dropout을 사용하였을 때 image에 noise를 추가하였을 때도 성능 하락의 폭이 적어지는 것을 볼 수 있습니다.