나의 정리
- 논문이 지적한 문제점
point cloud를 raw data로써 사용하지 않고 voxelization 등을 하고 사용을 해왔습니다. 이는 불필요하게 data가 많아지게 됩니다. - 해결 방안
따라서 point cloud를 곧바로 input data로 사용하는 model을 고안하였습니다.
Introduction
이전까지 point cloud를 사용할 땐 voxel이나 mesh로 변환을 시킨 다음 input data로 사용을 하였습니다. 하지만 변환을 시키면 data가 불필요하게 많아지고 natural invariance가 모호해집니다.
따라서 이 논문에서는 point cloud를 곧바로 input data로 사용하는 방법을 소개합니다.
point cloud는 두 가지 특성이 있습니다.
첫째 순서가 없는 data라는 점입니다. 순서가 없기 때문에 다른 순서로 point를 사용하더라도 같은 값을 출력해야 하고 이를 permutation invariant라 합니다. 그렇기 때문에 Symmetric function (대칭 함수)를 사용합니다.
→ Symmetric function 자체가 f(x, y, z) = f(y, z, x)를 만족하는 함수를 의미합니다.
둘째 단순한 점들의 집합입니다. 따라서 Rigid motion invariance합니다. 이때 rigid motion이란 크기와 각도가 보존되는 transformation을 의미합니다. 따라서 point에 rigid motion translation을 하여도 point 간의 거리 같은 특성이 변하지 않습니다. 이러한 특성 때문에 Joint Alignment Network를 사용합니다.
Method

PointNet은 먼저 단순하고 통합된 구조를 사용하기 때문에 쉬운 학습으로 여러 task를 수행할 수 있습니다.
→ classification, part segmentation, semantic segmentation

PointNet의 architecture입니다. network를 보시면 classification network, segmentation network로 크게 두 개의 network로 구성되어있습니다.
여기서 세 가지의 key module이 존재합니다.
- Symmetry Function (max pool)
- Local and Global information Aggregation
- Joint Alignment network
이제 각각의 module에 대해서 좀 더 자세히 설명해보겠습니다.
Symmetric function
앞서 설명한 Permutation invariance를 만족시키기 위한 세가지 방법이 존재합니다.
- input point cloud를 재정렬한다.
→ 높은 차원에서 point perturbation (point가 noise로 조금 흔들리는 것) 시에 안정적인 정렬이 불가능합니다. - 모든 순서에 대해서 augmentation을 하여 Sequence로 학습한다.
→ augmentation으로 인해 data의 수가 폭발적으로 증가해 불가능합니다. - Symmetric function을 사용합니다.
→ 이 방법이 가장 좋은 방법이라고 소개합니다.

위의 표를 보면 unsorted, sorted, sequence에 대한 accuracy가 나옵니다. sequence가 accuracy가 가장 높지만 data의 수가 많아서 사용하지 않고 symmetric function 중 Max pooling의 score가 가장 높을 것을 볼 수 있습니다.

따라서 전체 구조에서 봤듯 column-wise max pooling을 진행합니다.
Local and Global information Aggregation
Segmentation을 진행하기 위해서 사용된 module입니다.
Segmentation에선 local 정보도 중요하지만 global 정보도 매우 중요합니다. 따라서 두 정보를 모두 사용하기 위해서 사용합니다.
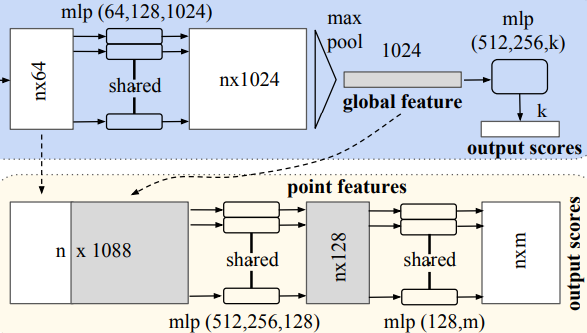
그저 간단하게 local feature에 classification network 마지막에 만들어진 global feature를 concatenate 하여 사용합니다.
Joint Alignment Network
앞서 설명했듯이 rigid motion invariance, 즉 Tranforamtion 적용 후에도 point 간의 관계를 유지해 같은 결과가 나오기 위해서 사용하는 network입니다.
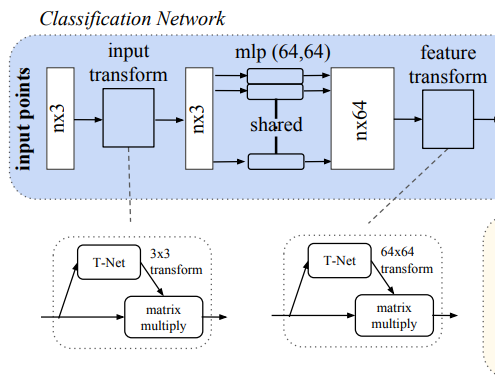
Point 각각에 canonical space로 변환할 수 있는 affine transformation matrix를 예측하여서 transformation을 진행합니다.
따라서 T-Net을 통하여 input matrix를 canonical space로 변환 할 수 있는 affine matrix (3x3, 64x64)를 prediction 하여 그 matrix를 input에 multiply 하여 진행합니다.
Spatial transform보다 feature transform의 경우 더 높은 차원이기 때문에 최적화에 어려움이 생깁니다. 따라서 regularization loss term을 추가하여서 학습을 진행합니다. loss의 식은 아래와 같습니다.

이를 통해서 더 안정적이고 높은 성능을 낼 수 있다고 합니다.