728x90
반응형
나의 정리
- Point Cloud를 이용하여 3D object detection을 진행하는데 point cloud encoding을 hyper parameter 없이 진행을 해 vertical 한 방향으로 encoding을 진행한다.
- 이러한 encoding 덕분에 3D Convolution이 아닌 2D convolution 연산이 가능해져 빠른 연산이 가능했다.
- end-to-end 학습이 가능한 3D object detection 방법이다.
- 3D detection을 하는 방법 중 voxel과는 다른 방식으로 접근하는 논문으로 다른 논문들에서 자주 언급되는 논문이다.
- 간단히 요약하면 voxel은 x, y, z를 단위로 나누어 grid 형태로 grouping을 했다면 pillar는 x, y에 대한 단위로 나누고 z 축으로는 한계가 없이 grouping을 한다.
이 때 z 축에 대한 정보가 사라질 수 있으니 추가적으로 pillar 내부의 point cloud 들의 평균 중심점 등 인코딩을 통하여 z 축 정보를 추가한다.
이를 통하여 BEV에서 보았을 때 2차원 평면의 정보로 만들 수 있고 이를 통해 2D Conv 연산을 가능하게 하였다.
Abstract
- Point cloud를 vertical 하게 encoding 하여 사용한다.
- 3D에서 2D로 바뀌게 되어 2D Convolution로 연산을 할 수 있어 연산량이 많이 줄어 속도가 빠르다.
Introduction
- point cloud를 사용하는 방법 중에는 많은 방법들이 있다.
그러나 point cloud는 sparse 하고 image는 2D지만, point cloud는 3D라서 image에서의 detection과 다른 점들이 있다.
point cloud를 Bird’s eye view(BEV)로 변환하여 사용을 하기도 하는데 이때의 장점
- Scal ambiguity를 줄일 수 있다.
→ 여러 각도나 위치에서 object의 scale이 다르게 보이는 것을 줄일 수 있다. - Oclussion을 줄일 수 있다.
하지만 단점도 존재한다.
- CNN network를 비효율적으로 만들어 더욱 sparse하게 만들 수 있다.
- 2D Convolution layer를 사용하여 end-to-end 학습을 하는 PointPillars를 제안한다.
PointPillars의 장점
- 고정된 encoder를 이용하는게 아닌 feature를 학습해 모든 point cloud 정보를 활용할 수 있다.
직접 vertical 방향으로 binning을 하지 않아도 된다. - 2D Convolution 연산이 가능하게 되어 매우 효율적이다.
lidar, radar 등 다른 point cloud를 사용할 때도 tuning이 필요하지 않다.
- KITTI dataset으로 평가
Related work
- Object detection using CNNs
- Object detection in lidar point clouds
- Contribution
- 3D object detection을 위한 end-to-end 학습이 가능한 point cloud encoder와 network인 PointPillars를 소개
- 2D Convolution 연산이 사용하여 다른 방법보다 빠르다.
- KITTI dataset에서 cars, pedestrians, cyclist의 BEV, 3D benchmark에서 SOTA 성능을 냈다.
- Ablation study에서 performance에 주요한 key factor가 뭔지 조사했다.
- Spatial binning에 따라 속도와 정확도의 명백한 Trade-off가 있다.
- 최소한의 Box augmentation이 좋은 효과를 보였다.
- X_p, Y_p를 추가한다. 이는 data augmentation에서의 variance를 감소시키고 안정성을 향상한다.
- Fixed Encoder에 비해 Bin size에 대해 더 강건하고 모든 면에서 높은 성능을 보인다.
PointPillars Network
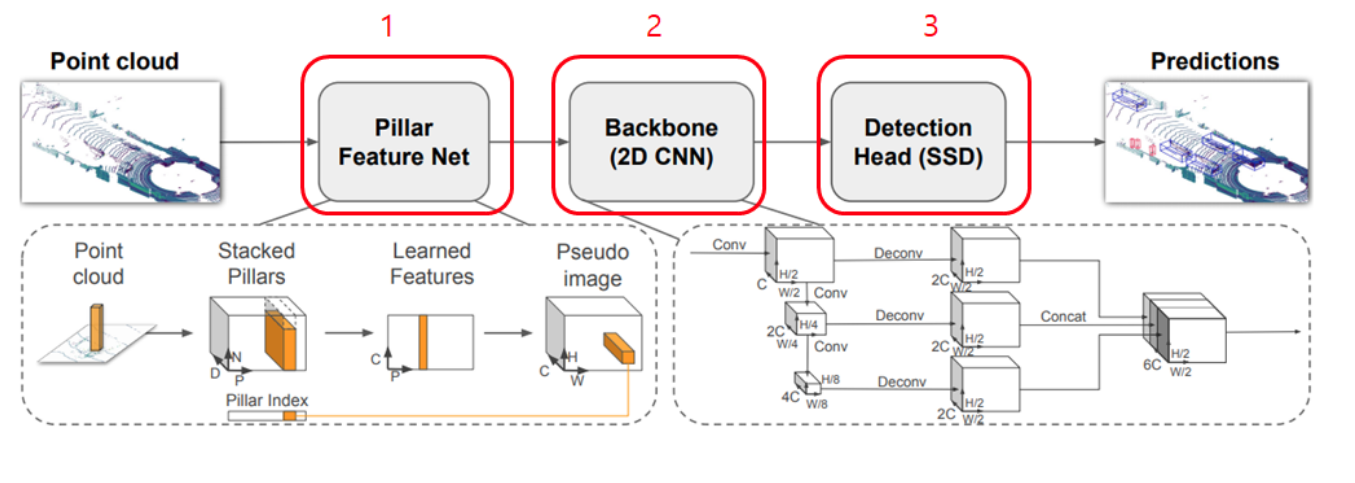
총 3개의 main stage로 구성된다.
- A feature encoder network that converts a point cloud to a sparse pseudo-image
- 2D convolutional backbone to process the pseudo-image into high-level representation
- detection head that detects and regresses 3D boxes
- Pointcloud to Pseudo-Image
- 2D Convolution 연산을 위해서 pseudo-image로 point cloud를 변환한다.
- point cloud → l = (x, y, z, r) , (r은 reflectance) 좌표로 구성되고 이를 pillars로 변환할 때는 z 축에 대한 limit가 없기 때문에 hyper parameter가 필요가 없다.
- pillar → (x, y, z, r, x_c, y_c, z_c, x_p, y_p) → 9 dimension으로 encoding 된다.
c는 pillar 안의 모든 point들의 arithmetic mean이다.
p는 pillar의 중심 좌표 x, y - pillar의 대부분은 비어있는 상태이다.
(Voxel과 마찬가지인 상태, sparse 한 특성 때문이다.) - (D, P, N)의 사이즈 tensor로 encoding 된다.
D → pillar의 coordinate
P → 샘플 당 non-empty pillar의 개수
N →pillar 당 point의 개수 - sample or pillar에 너무 많은 data가 있을 땐 Random Sampling을 진행하고 적을 땐 Zero Padding을 진행한다.
- Batch Norm과 ReLU를 지나서 최종적으로 (C, P, N) size의 tensor를 생성한다.
그 이후 channel에 대해 max pooling을 이용해 (C, P) size tensor를 생성한다. - Encoding을 한 후에 original pillar의 위치로 feature들을 돌려놓아 (C, H, W)의 pseudo-image를 생성한다.
- Backbone
- backbone은 두 가지 sub-network로 이루어진다.
- one top-down network that produces features at increasingly small spatial resolution (Top-down network는 점점 작은 spatial resolution feature를 생성한다.)
- performs upsampling and concatenation of the top-down features (Top-down network의 feature를 upsampling 하고 concatenation 한다.)
- top-down backbone은 Block(S, L, F)가 연속적으로 이루어져 있다.
S →stride
L → 3x3 2D Conv-layers
F → Output channels - First Conv layer는 block의 stride size를 바꿔주기 위해서 S/Sin으로 stride를 한다.
그다음 block 내의 모든 Conv는 stride 1로 계산한다. - Top-down network로 나온 feature를 transposed 2D Conv, BN, ReLU를 사용해 Upsampling (Sin, Sout, F)를 한다. (F는 final feature)
- 마지막엔 이 feature들을 concatenate 하여 이 결과물은 다른 stride로부터 생성된 feature들의 모음이 된다.
- Detection Head
- SSD를 사용하여 3D object detection을 하였다.
- 2D와 차이점은 height, elevation이 추가된 regression target으로 사용되었다.
Implementation Details
- Network
- initialize는 uniform distribution을 사용해 random 하게 initialize 했다.
- Encoder Network는 C=64의 Output feature를 가지고 Car와 Pedestrian/cyclist 각각에 대해 backbone은 첫 번째 block에서의 stride(car → S=2, ped/cyc → S=1)를 제외하고는 같다.
- 각각의 network는 3개의 Block(Block 1(S, 4, C), Block(2S, 6, 2C), Block 3(4S, 6, 2C))로 이루어져 있고 각각 Block들 또한 Upsampling (UP1(S, S, 2C), UP2(2S, S, 2C), UP3(4S, S, 2C))을 한 후에 concatenated 되어 총 6C개의 feature가 detection head에 사용된다.


- Loss
- SECOND에서와 같은 loss function을 사용하고 GT와 anchor는 (x, y, z, w, h, l, theta)로 정의된다.
-
- Loss는 위와 같이 계산되고 angle localization 만으로는 뒤집어진 box들을 구별하지 못하여 softmax classification을 통하여 heading을 학습시킨다.
- P^a는 anchor의 class probability이고 해당 논문에서는 alpha = 0.25, gamma = 2로 세팅했다.

- 위의 식이 total loss이고 Npos는 positive anchor의 수이고 B_loc=2, B_cls=1, B_dir=0.2로 하였다.
Loss function은 Adam으로 optimize 하였으며 initial LR rate는 2*10^-4로 10 epoch마다 0.8의 factor로 decay 하였다.
epoch는 160과 320, batch size는 2와 4로 각각 val, test를 진행했다.
Experimental setup
- Dataset
- Settings
- Data Augmentation
Results
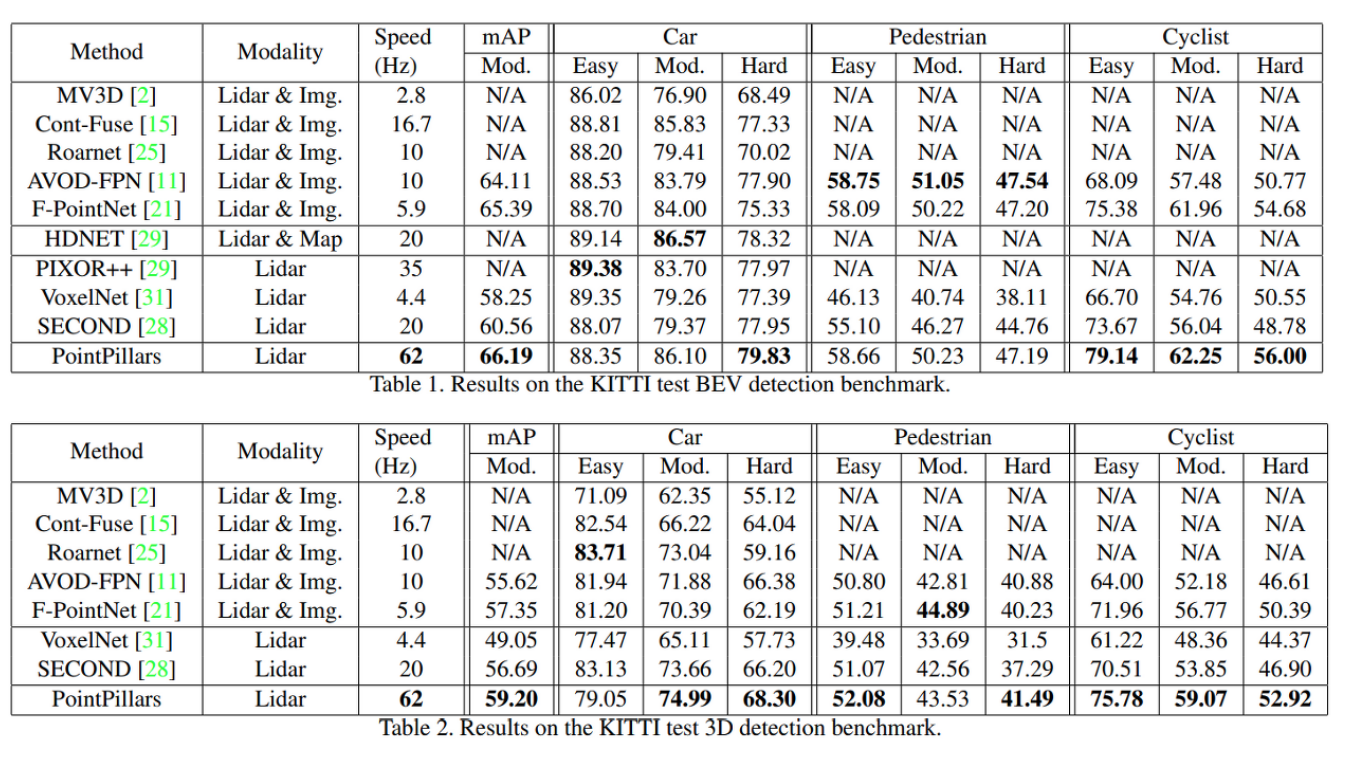
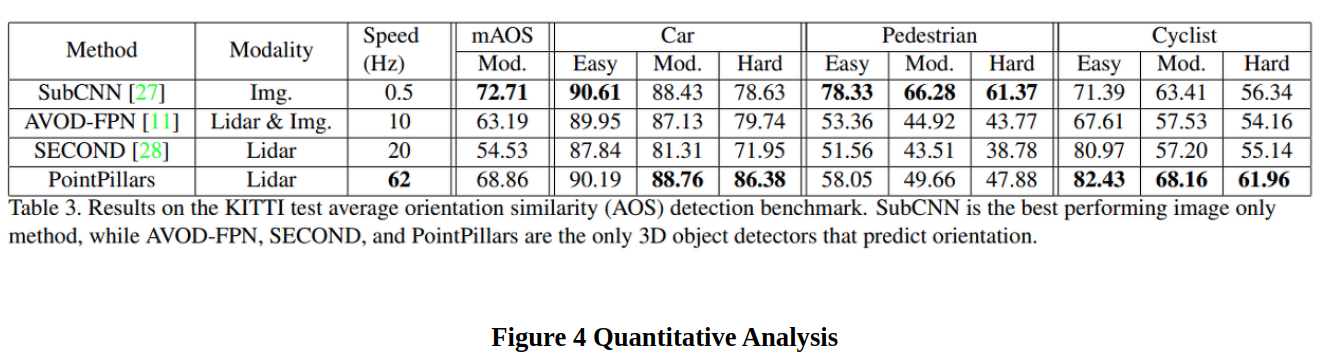
Ablation Studies
- Spatial Resolution
- Per Box Data Augmentation
- Point Decorations
- Encoding
728x90
반응형