[논문 리뷰] PETRv2: A Unified Framework for 3D Perception from Multi-Camera Images (Arxiv, 2022)
나의 정리
- 논문이 지적한 문제점
기존의 PETR에서 생성하던 3D Position Embedding은 data-independent 합니다. 또한 시간 축에 대한 정보도 사용하고 있지 않습니다. 보다 정확한 3D object detection을 위해서 Temporal modeling과 3D position Embedding을 구하는 방식을 개선합니다. - 해결 방안
3D PE를 생성할 때 2D image feature로 guidance를 주어 생성합니다. 또한 Temporal modeling을 위해서 이전 frame의 3D coordinate을 현재 frame의 3D coordinate으로 맞춰주기 위해 pose transformation을 통해 temporal alignment를 진행합니다. 또한 multi-task learning을 위해 sparse task-specific query를 사용하여 3D object detection, BEV segmentation, 3D lane detection을 수행합니다.
하지만 개인적으로 실험이 매우 부족하다고 생각이 들었습니다.
Abstract
PETR 기반에 이전 frame의 Temporal 정보를 활용하여 3D object detection의 성능을 높인 모델입니다. 기존의 PETR에서 사용한 3D position embedding에 각각의 frame의 object 위치를 align 시키기 위해서 temporal modeling을 해줍니다.
feature-guided position encoder를 사용해 image feature로 guidance를 주어 3D Position Embedding을 좀 더 adaptive 하게 생성할 수 있게 해 주었습니다.
multi-task learning(BEV segmentation, 3D lane detection, 3D object detection)을 진행하는데 각각의 task를 위한 task-specific query를 서로 다른 space에서 생성하여 효과적인 성능을 냈습니다.
Introduction
지금까지 Multi-camera 기반의 3D perception 모델들은 BEV-based, DETR-based 두 가지로 나뉘어서 발전되어 왔습니다.
BEV-based (BEVDet) 방식은 multi-camera view를 BEV로 변환시키기 위해 explicit 한 방식인 LSS 방식을 사용하여 BEV feature를 생성하는 방식입니다.
DETR-based (BEVFormer) 방식은 object query와 hungarian algorithm으로 end-to-end 방식으로 학습하는 방식입니다.
DETR-based 방식인 PETR의 경우엔 2D feature에 3D coordinate 정보를 추가적으로 인코딩하여 3D position-aware feature를 생성하여 object query와 cross-attention을 통해 3D object detection을 진행하는 방식이었습니다. 해당 논문에서는 PETR에서 temporal modeling과 multi-task learning을 추가하여 확장한 PETR v2를 제안합니다.
Temporal modeling을 위해서 3D 공간 상에서 서로 다른 frame의 object 위치를 정렬(align)을 해야 합니다.
BEVDet4D의 경우 pose transformation 방식을 사용해서 현재 frame과 이전 frame의 BEV feature를 explicit 하게 정렬합니다.
하지만 PETR의 경우 implicit 하게 3D coordinate 정보를 2D feature에 인코딩하여 explicit 하게 feature transform을 하지 않았습니다. 따라서 해당 논문에서는 PETR에서 사용한 3D positional encoding이 temporal alignment에도 효과가 있는지 분석합니다.
Multi-task learning을 위해서 해당 논문에서는 각기 다른 task를 위해서 각기 다른 space 상에 생성되는 sparse task-specific query를 사용합니다. 예를 들어 3D lane detection을 위해서 3D space 상에서 anchor lane 스타일의 lane query를 사용하고 BEV segmentation을 위해선 BEV space 상에 seg query를 생성합니다. sparse task-specific query들을 같은 transformer decoder의 입력으로 사용해 해당 query를 update 하고 각기 다른 task-specific head를 통과시켜 prediction 결과를 얻습니다.
또한 PETR에서 사용했던 3D positional embedding(PE) 값의 경우 camera frustum space 상에 뿌린 3D point들을 각 camera view의 matrix를 사용해 3D space 상으로 만들어줬습니다. 따라서 생성된 3D PE의 값은 data에 독립적으로 생성된 값입니다. PETRv2에서는 feature-guided position encoder (FPE) 모듈을 사용하여 image feature를 같이 사용하여 data에 종속적인 3D PE 값을 인코딩해주는 방식으로 진행합니다.
PETRv2의 contribution을 정리하면 아래와 같습니다.
- temporal modeling을 하기 위해선 temporal alignment가 필요한데 이를 3D PE의 pose transformation을 통해서 정렬을 해주었고 2D image feature의 guidance를 통해 3D PE를 생성하였습니다.
- task-specific query를 사용하여 multi-task learning(BEV segmentation, 3D lane detection)을 수행하였습니다.
- 3D object detetion, BEV segmentation, 3D lane detection에서 모두 SOTA를 달성하였습니다.
Method
Overall Architecture
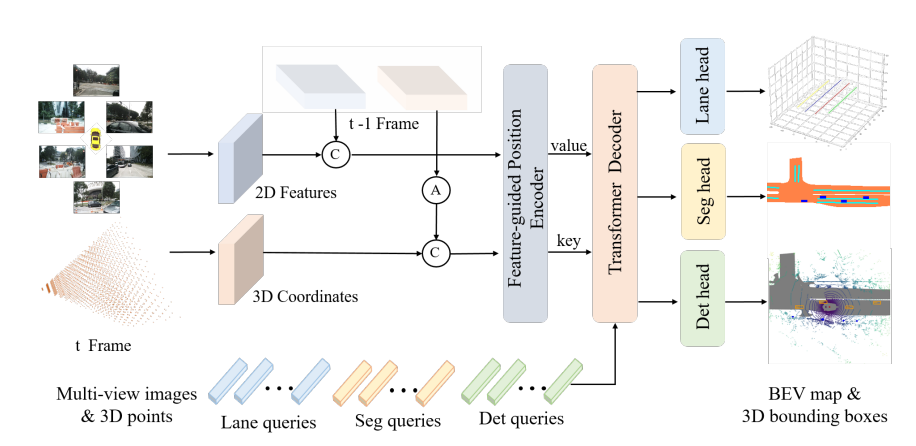
PETRv2의 전체 구조는 위와 같습니다. PETR 기반으로 Temporal modeling과 multi-task learning으로 확장된 구조를 가집니다.
pipeline을 간단히 소개하면 아래와 같습니다.
2D backbone (ResNet-50)으로 추출된 2D feature와 PETR과 동일한 방식으로 3D coordinate을 생성합니다. 그다음 인접한 frame (t-1)의 2D feature와 3D coordinate 정보를 concatenate(C)하여 FPE의 입력으로 사용하는데, 이전 frame의 3D coordinate는 Pose transformation(A)를 거친 뒤 현재 frame의 3D coordinate과 concatenate(C)합니다. 이후 task-specific query를 사용하여 Transformer decoder로 update 한 뒤 각 task를 위한 head를 통과시켜 최종 prediction을 생성하는 방식으로 진행됩니다.
Temporal Modeling (3D Coordinates Alignment)
Temporal modeling을 위해서 이전 시점 t-1 frame과 현재 시점 t frame 간의 3D coordinate Alignment가 필요합니다.
해당 논문에서는 t시점의 camera coordinate을 $c(t)$, lidar coordinate을 $l(t)$, ego coordinate을 $e(t)$, global coordinate을 $g$라고 표현하고 source coordinate system에서 target coodinate system으로 변환하는 transformation matrix를 $T^{dst}_{src}$ 라고 표현합니다.
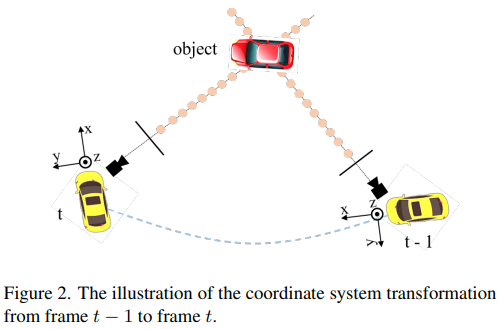
해당 논문에서는 $l(t)$ 를 3D position-aware feature의 기준 3D space로 사용합니다. 따라서 i번째 camera에서 projection 된 3D point $P_i^{l(t)}(t)$ 는 아래의 식(1)으로 나타낼 수 있습니다.
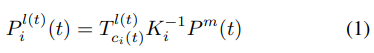
→ $P^m(t)$ 는 t frame의 camera frustum space의 meshgrid입니다. 따라서 (1)의 식은 meshgrid를 lidar coordinate로 projection 한 3D point를 의미합니다.
temporal modeling을 위해 t-1 frame의 coordinate을 t frame coordinate과 맞춰주기 위해서 아래의 식(2), (3)을 사용합니다.
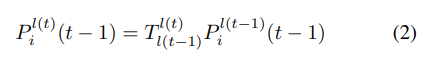
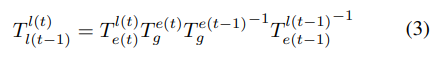
(2)식을 이용하여 t-1 frame의 lidar coordinate 상의 3D point를 현재 시점 t의 lidar coordinate에 맞춰
줍니다. 여기서 사용되는 transformation matrix $T^{l(t)}_{l(t-1)}$ 는 (3) 식을 이용하여 구합니다.
t-1 frame과 t frame을 맞춰주기 위해서 먼저 t-1 frame coordinate을 t-1 frame의 ego coordinate, global coordinate, t frame의 ego coordinate, t frame의 lidar coordinate 순으로 변환합니다. 해당 논문에서는 global coordinate space의 경우 t-1 frame과 t frame coordinate을 이어주는 중간 다리 역할이 되어 줄 수 있어서 해당 방식으로 변환을 하였다고 합니다.
이렇게 coordinate가 맞춰진 point set $[P^{l(t)}_i(t-1), P^{l(t)}_i(t)]$ 를 사용하여 3D PE을 생성합니다.
BEV Segmentation (Multi-task Learning)
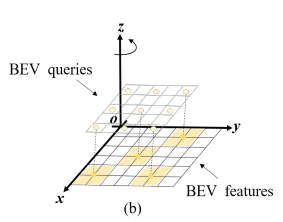
위 그림처럼 고해상도의 BEV map은 작은 patch들로 나뉠 수 있습니다. 이렇게 나눠진 각 patch의 label을 예측하는 방식으로 BEV segmentation을 수행합니다. 따라서 200x200 크기의 BEV map 결과를 생성하기 위해서 위 그림과 같이 BEV space에 고정된 위치의 anchor point를 초기화하고 해당 anchor point를 두 개의 MLP를 통과시켜 seg query를 생성합니다. →patch size는 25x25로 설정하고 총 625개의 seg query를 사용합니다.
3D Lane Detection (Multi-task Learning)
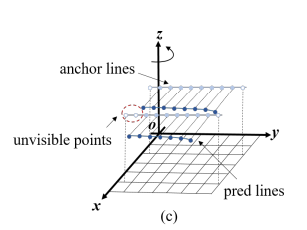
3D lane detection을 수행하기 위해서 lane query를 추가하였습니다. 3D anchor lane을 3차원 coordinate의 집합 $l=\{(x_1,y_1,z_1),(x_2,y_2,z_2), \dots ,(x_n,y_n,z_n)\}$ 으로 표현하였습니다.
PersFormer에서 사용했던 방식과 비슷하게 Y 축을 따라 균일하게 샘플링한 고정된 샘플링 포인트 집합을 사용합니다. 하지만 기존 방식과 약간 다르게 각각의 anchor line에 대해 서로 다른 기울기를 미리 정의했다고 합니다.
Feature-guided Position Encoder
PETR에서 개인적으로 왜 image feature를 사용하지 않고 3D PE를 생성할까 의문이 많았는데 PETR v2에서는 image feature를 사용해서 3D PE를 생성합니다.
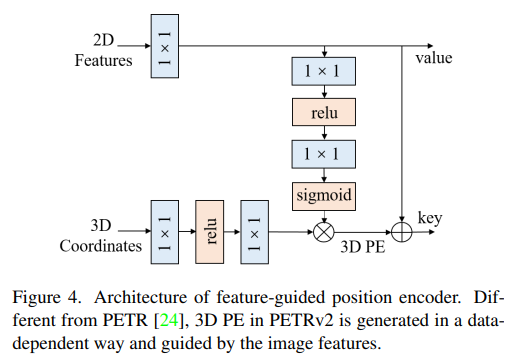
앞서 인접 frame과 concatenate 한 2D feature, 3D coordinate을 위 과정을 거쳐서 최종 3D PE를 생성합니다.
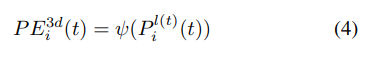
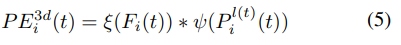
$\psi(\cdot)$ 와 $\xi$ 는 MLP, $P^{l(t)}_i$ 는 t frame의 i번째 camera view lidar coordinate 상의 3D point, $F_i(t)$ 는 i번째 카메라의 2D feature를 의미합니다.
식 (4)는 data-independent 하게 3D PE를 생성하던 기존 PETR의 식입니다. PETR v2에서는 image feature에서 depth 정보와 같은 의미 있는 guidance를 주기 위해서 2D feature를 사용하여 3D PE를 생성합니다.
식 (5)를 보면 2D feature를 MLP (1x1 conv)를 통과시키고 sigmoid를 최종적으로 통과시킨 값과 기존의 MLP (1x1 conv)를 통과시킨 값을 곱해주어서 최종적인 3D PE를 생성합니다.
이후 tranformer decoder로 들어갈 때는 3D PE 정보를 2D feature에 더 해주어서 key로 사용하고 원래 2D feature 값을 value로 사용합니다.
Robustness Analysis
자율 주행에서의 safety와 reliability를 위해서 sensor error와 system bias에 대한 robustness를 평가하기 위해서 대표적인 3가지 sensor error 상황에 대해서 실험을 진행합니다.
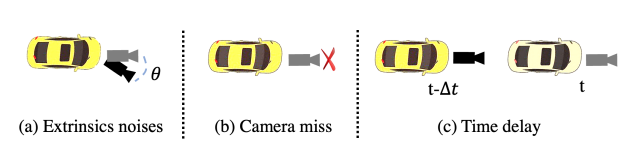
- Extrinsics noises
차가 운행함에 있어서 점점 sensor의 위치가 흔들리면서 원래의 extrinsic matrix가 바뀌게 되어 부정확한 결과를 초래하는 경우가 실제 주행환경에선 빈번하게 일어납니다.
해당 상황을 가정하기 위해서 camera extrinsic을 랜덤 하게 3D rotation을 적용하였습니다. 좀 더 구체적으로 multi-camera 중 한 camera에만 해당 rotation을 적용하였습니다.
→하나의 카메라에만 적용한 건 좀 부족한 실험이지 않나 생각이 듭니다. - Camera miss
multi-view camera 중 고장 난 카메라가 있는 상황입니다. sensor redundancy에 대한 평가가 진행됩니다. - Time delay
밤과 같이 어두운 경우에 셔터 속도가 느려 camera에 time delay가 생기는 상황입니다.
Experiments
Implementation Details
image backbone으로 ResNet, VoVNetV2, EfficientNet을 사용했습니다.
이전 frame을 사용할 때 $[3T, 27T]$ $T(\approx0.083)$ 범위의 frame을 사용하였습니다.
3D object detection을 위해서 1500개의 det query를 사용하였습니다.
FCOS3 D에서 사용한 것 처럼 추가적인 disentangled regression layer를 사용하였습니다.
BEV segmentation을 위한 seg query는 200x200 BEV map 생성을 위해 25x25 patch size로 나눠 625개의 query를 생성합니다.
3D lane detection을 위해서 image size를 360x480로 사용하고 100개의 lane query를 사용합니다.
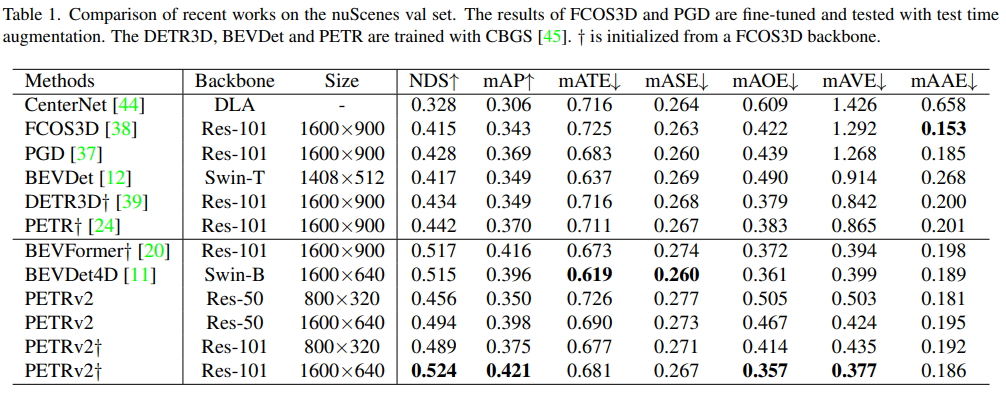
PETR v2 성능을 보면 먼저 FCOS3D backbone을 사용했을 때 SOTA 성능을 냈고 temporal modeling을 하였기 때문에 기존의 PETR보다 mAVE가 큰 폭으로 하락한 것을 볼 수 있습니다.
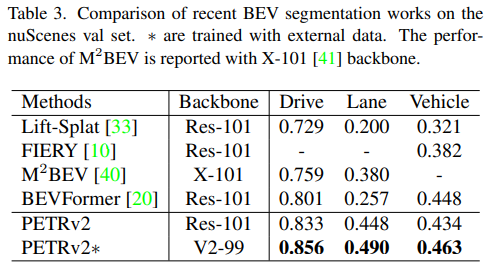
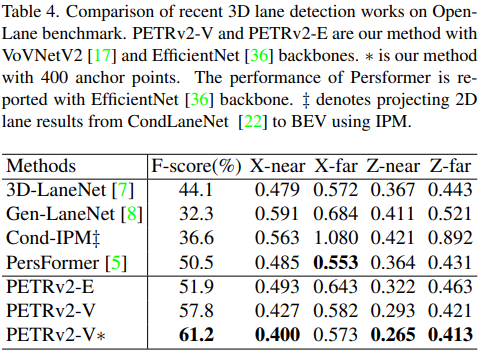
각각 BEV segmentation과 3D lane detection 성능 결과도 비교하였고 모두 SOTA 성능을 냈습니다.
Ablation Study
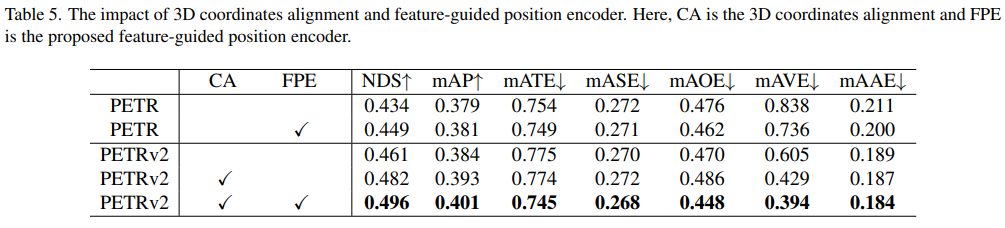
3D coordinate alignment(CA)와 feature-guided position encoder(FPE)에 대한 ablation study를 진행하기 위해서 3D object detection branch만 학습을 시켜 비교했다고 합니다. 기존의 PETR에 FPE만 사용하여도 성능 gain이 존재하였고 temporal modeling을 위한 CA를 사용하면 큰 성능 gain이 존재하였습니다. CA, FPE를 모두 사용하였을 때 mAP에서 큰 성능 gain이 있었습니다.
따라서 논문에서는 Temporal modeling을 하였을 때 FPE가 mAP에서 더 큰 성능 gain이 있었으므로 PETR v2에서 더 효과적이라고 설명했습니다.
Ablation study에서 아쉬운 점은 각 multi-task learning을 어떻게 조합하는지에 따른 성능 gain에 대한 실험이 없는 것이 가장 아쉬웠습니다.
Robustness analysis
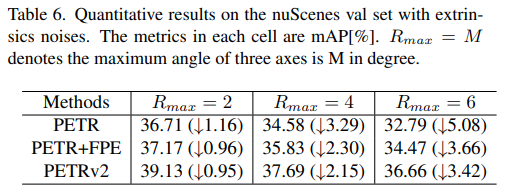
실험 1번 환경인 extrinsic matrix에 random rotation을 한 결과입니다. 기존 PETR에 FPE만 적용해도 성능 하락폭이 감소하는 것을 볼 수 있습니다. 거기에 temporal modeling까지 더하면 robustness가 더 증가한다고 설명하고 있습니다.
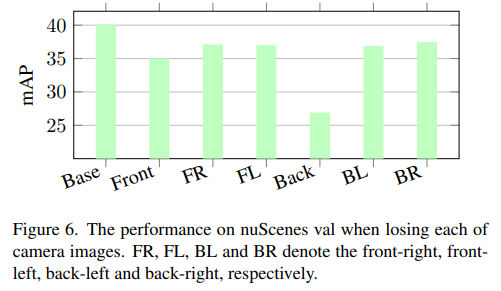
6개의 카메라 중 하나의 카메라를 랜덤 하게 사용하지 않았을 때의 성능 결과입니다. 성능 하락률이 크지 않다고 설명하지만 기존 PETR의 성능이 나와있지 않아 납득이 되는 실험 같지는 않습니다.
Back view에 대한 성능이 많이 떨어지는 것을 볼 수 있는데 논문에서는 Back camera의 경우 FOV가 120도로 크기 때문에 생기는 큰 성능 하락이라고 설명합니다.
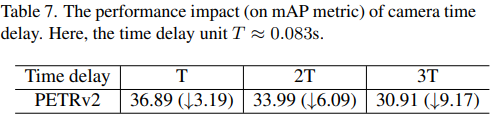
위 실험에서는 Time delay에 대한 robustness인데 Time delay가 커짐에 따라 성능 하락 폭이 존재한다고 설명하는데 이 또한 비교군이 없어 납득되는 실험은 아닌 것 같습니다.