[논문 리뷰] PETR: Position Embedding Transformation for Multi-View 3D Object Detection (ECCV, 2022)
나의 정리
- 논문이 지적한 문제점
기존 transformer에서 사용되던 Position Embedding은 image의 2D space 상에 대한 position information을 encoding 하는 것입니다.
하지만 우린 3D space 상의 feature를 생성하기 때문에 2D position information을 feature에 encoding하는 것은 큰 도움이 되지 못합니다. 또한 기존의 DETR3D는 object query에 해당하는 reference point position을 예측하고 해당 위치의 2D feature를 sampling 하는데 예측한 reference point position이 정확하지 않을 수 있습니다. - 해결 방안
PETR은 2D feature map에 3D space에 대한 position information을 encoding하여 3D position-aware feature를 생성합니다. 이 3D feature와 object query가 interaction 하여 query update를 진행하고 이후 end-to-end로 3D detection을 수행합니다. 간단한 feature sampling과 position embedding 과정을 통해 성능 향상을 달성했습니다.
Abstract
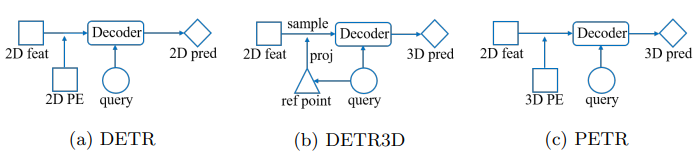
PETR은 Transformer 기반 detector가 2D feature를 가져오는 방식에 대한 문제를 제기합니다.
대표적인 DETR 3D에서는 object query로 reference point의 3D 좌표를 예측합니다. 이후 image로 projection 시켜 해당 위치의 2D feature를 sampling 해오게 됩니다. 하지만 이렇게 reference point 위치를 예측한 뒤 sampling을 해오면 부정확한 위치에서 feature를 sampling 하게 됩니다.
따라서 해당 논문에서는 3D 좌표의 정보를 image feature에 encoding 해주어 3D position-aware feature를 생성합니다. 이를 통해 object query가 3D position aware feature를 사용해 object query를 update하고 end-to-end로 detection을 진행합니다.
Introduction
Abstract에서 언급했듯 기존 DETR3D에서 예측하는 reference point 좌표가 정확하지 않을 수 있고 projection 시킨 위치의 feature만 sampling 해오기 때문에 global view의 학습에서는 큰 도움이 되지 않습니다.
PETR은 Implicit Neural Representation(INR)에서 영감을 받았다고 합니다. 기존의 MetaSR, LIFF (super-resolution 논문)에서는 High resolution RGB image의 coordinate 정보를 Low-resolution feature에 encoding을 해서 High resolution RGB pixel 값을 얻습니다. 이와 비슷하게 PETR은 2D feature map에 3D coordinate 정보를 encoding 해서 3D 상에서의 feature를 얻도록 설계하였습니다.
이 논문에서는 3D position embedding으로 multi-view image로 얻은 2D feature를 3D representation으로 transform 하는 것을 목표로 합니다. 해당 목표를 위해 아래와 같은 과정을 거쳐 encoding 해줍니다.
- camera frustum space를 meshgrid 좌표로 먼저 discretize를 진행합니다.
- 각 meshgrid 좌표를 camera calibration matrix를 사용하여 3D 좌표로 변환합니다.
- backbone을 통과시켜 얻은 2D image feature와 3D 좌표를 3D position encoder에 넣어 3D position-aware feature를 생성합니다.
PETR의 contribution을 정리하면 아래와 같습니다.
- 3D coordinate에 대한 postional embedding을 2D feature에 해줘 간단한 방식으로 3D domain으로 변환하는 방법을 제안했습니다. Object query가 3D position-aware feature를 사용하여 update되고 최종적으로 end-to-end로 detection을 진행합니다.
- nuScenes dataset에서 SOTA 성능을 냈습니다.
Method
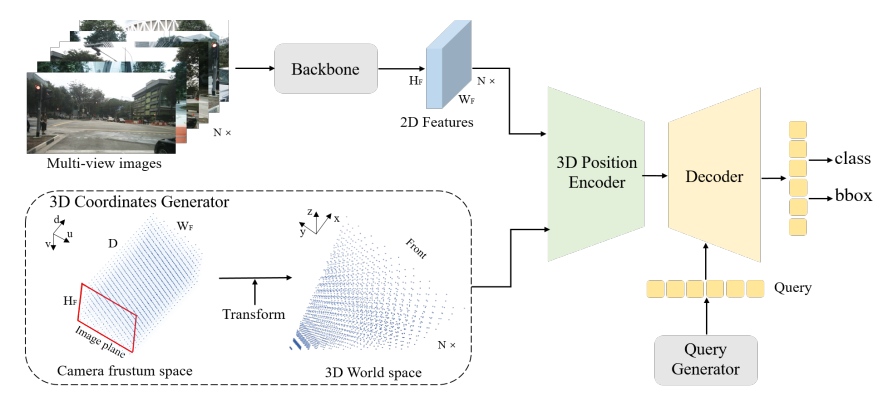
전체 구조를 보면 위와 같습니다. 3D coordinate generator로 생성된 3D 좌표들과 2D feature를 3D position encoder로 3D position-aware feature를 생성하고 object query와 cross-attention을 통해 최종적인 detection을 하는 간단한 모델 구조를 제안합니다.
3D Coordinates Generator
2D image와 3D space 사이의 관계를 구하기 위해서 camera frustum space의 point를 3D space로 projection 시킵니다. (두 space는 서로 one-to-one matching 입니다.)
먼저 camera frustum space를 $(W_F,H_F,D)$ size의 meshgrid로 나눠줍니다. meshgrid 안의 각 point는 $p_j^m=(u_j\times d_j,v_j\times d_j,d_j,1)^T$로 표현될 수 있습니다.
($d_j$는 depth value, $(u_j,v_j)$는 pixel 좌표입니다.)
meshgrid point로 reverse 3D projection, $p_{i,j}^{3d}=K_i^{-1}p_j^m$의 식을 사용해 3D 좌표 $p_{i,j}^{3d}$를 생성합니다. 여기서 생성한 3D space는 모든 multi-view를 공유합니다. 따라서 i는 i번째 image를 의미합니다.
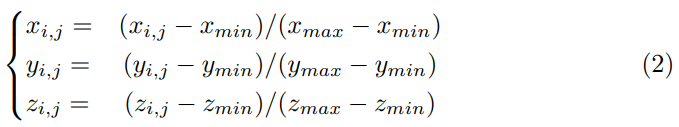
이후에 (2)번 식을 사용해 3D 좌표를 normalize 해서 사용합니다. 최종적으로 우리가 얻은 normalized coordinate은 $P^{3d}=\{P_i^{3d}\in R^{(D\times 4)\times H_F\times W_F},i=1,2,\dots,N\}$의 형태를 가집니다.
(D는 depth로 camera frustum space의 depth를 discretize 한 값입니다.)
3D position Encoder
3D position encoder는 2D feature와 3D position 정보를 결합하여 3D feature를 얻기 위해 사용합니다.
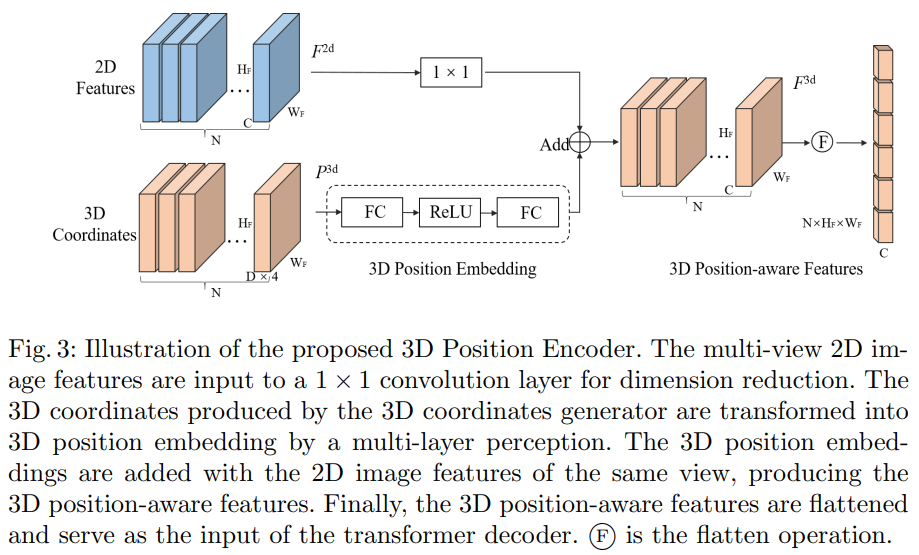
encoder의 구조는 위와 같이 생각보다 단순합니다.
3D position은 MLP를 태워서 3D position Embedding으로 변환합니다. 2D feature는 dimension을 맞춰주기 위해서 1x1 convolution을 통과시킨 뒤 앞서 생성한 3D PE를 더해줘서 3D position-aware feature를 생성합니다. 이후에 flatten 하여 decoder에서 사용합니다.
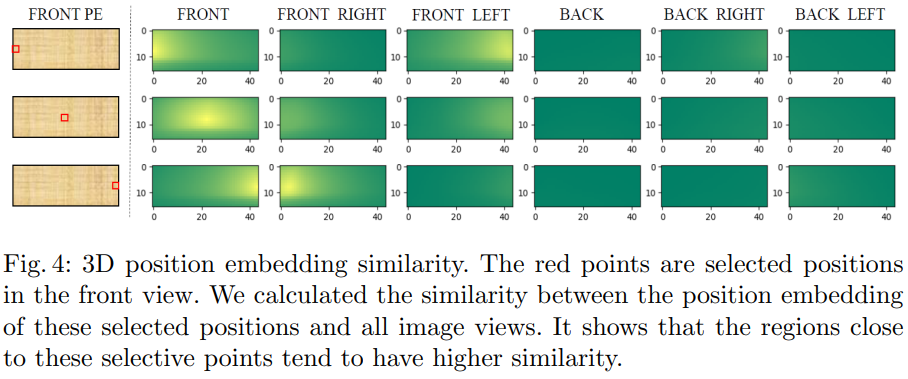
여기서 제안한 3D PE를 분석한 표입니다. front view에서 3개의 point를 sampling 해서 해당 3D PE를 다른 3D PE들과 유사도를 분석한 시각화한 결과입니다. 첫 번째 행을 보면 front view에서 왼쪽 point를 sampling 하였을 때 Front Left view의 오른쪽과 유사도가 높은 것을 볼 수 있습니다. 이를 통해서 통합된 3D space에 대해서 position embedding이 잘 되었다고 주장합니다.
Query Generator
2022 AAAI에 발표된 Anchor-DETR에서 query를 생성하는 방법을 PETR에서도 사용합니다.
먼저 uniform 하게 3D world space에 learnable anchor point를 initialize합니다. 그 다음 3D anchor point를 작은 MLP network를 통과시켜 object query를 생성하도록 합니다.
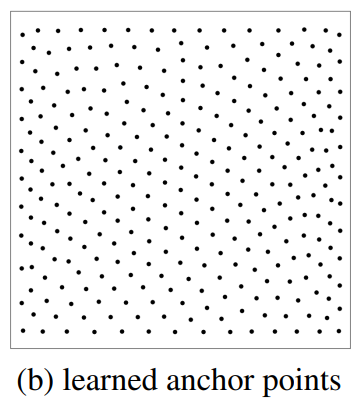
anchor point가 학습을 통해서 위와 같이 uniform하게 분포하는 게 아닌 object가 있을 법한 곳으로 이동하게 됩니다. 따라서 anchor point를 도입하여 object가 있을 법한 위치에 object query를 생성할 수 있게 됩니다.
이를 통해 DETR 세팅으로도 수렴을 잘 시킬 수 있고 detection 성능도 올릴 수 있었다고 합니다.
Decoder
decoder layer로 DETR에서 사용되었던 decoder 그대로 L개를 사용합니다.
$Q_l=\Omega_l(F^{3d},Q_{l-1}),l=1,\dots,L$ 을 사용하여서 l번째 layer의 object query$Q_l$를 update 합니다. $\Omega_l$은 l번째 decoder layer입니다. 간단하게 3D position-aware feature와 object query를 cross-attention을 통해 update 하는 방식을 사용합니다.
Head and Loss
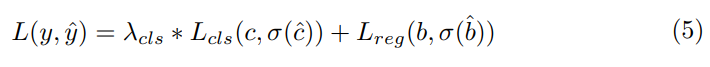
decoder에서 생성된 object query를 사용해 classification과 regression을 진행합니다. 또한 regression branch에서 해당하는 anchor point의 좌표를 수정하는 offset을 함께 예측하여 anchor point를 수정합니다.
Experiments
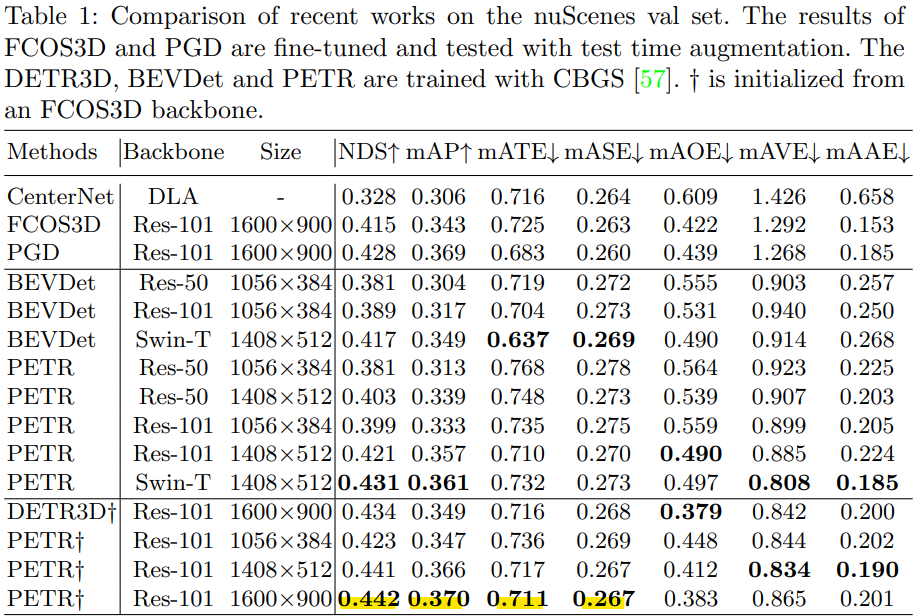
다른 SOTA 모델들과 비교한 표입니다. image backbone 마다 성능 차이가 있지만 다른 SOTA 모델과 같은 backbone을 사용하더라도 높은 성능을 내는 것을 볼 수 있습니다.
Ablation Study
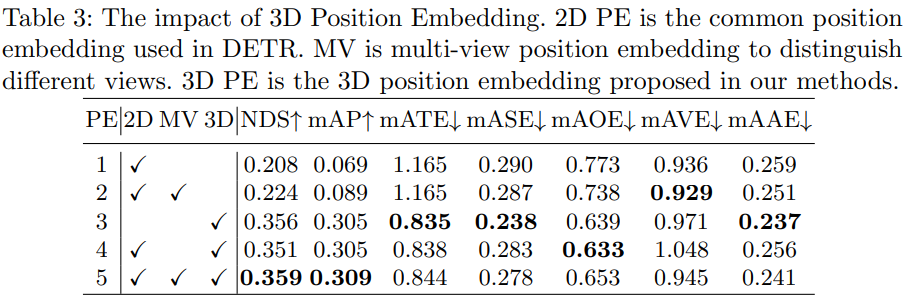
ablation study로 3D PE를 사용했을 때 가장 성능 gain이 컸고 2D PE, multi-view PE, 3D PE를 모두 사용하였을 때의 NDS가 가장 높았습니다.

(a)는 3D PE를 구하기 위해서 MLP를 사용한다고 했는데 해당 layer에 대한 실험입니다. 3x3 size의 convolution을 사용했을 때 오히려 2D feature와 3D position 간의 관계를 망쳐버리기 때문에 성능이 매우 낮게 나오는 것을 볼 수 있었습니다. 따라서 저자들은 1x1 convolution layer를 사용하여 다른 spatial 한 정보와 섞이지 않게 하였습니다.
(b)는 3D PE와 2D feature의 fusion 방식에 대한 실험입니다. 단순하게 더하는 것이 가장 높은 성능을 냈다고 합니다.
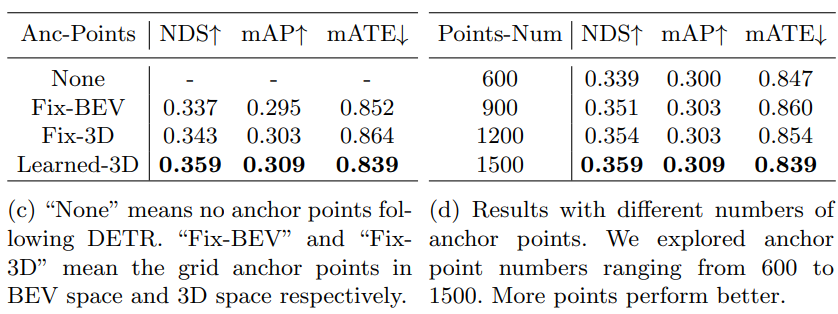
(c), (d)는 object query generation시 사용되었던 anchor point 관련 실험들입니다. anchor point를 고정하여 사용하는 것이 아닌 learnable 하게 사용함으로써 성능을 높일 수 있었고 point의 개수도 많으면 많을수록 좋았다고 합니다. 하지만 너무 많으면 또 좋지 않아서 trade-off를 고려해서 1500개를 사용했다고 합니다.