[논문 리뷰] Pseudo-Stereo for Monocular 3D Object Detection in Autonomous Drivin (2022)
나의 정리
- 논문이 지적한 문제점: 기존의 monocular 3D object detection을 위해서 Pseudo-LiDAR 방식을 사용하는 경우엔 image로 너무 다른 modality를 가지는 LiDAR data를 생성하는데 많은 오류가 생기고 그로 인하여 성능 저하를 겪게 됩니다.
- 해결 방안: 따라서 input image로 virtual right image를 생성하여 기존의 Stereo 3D object detector를 통과시켜 3D object detection을 진행합니다. 이때 image를 생성하는 방법을 image-level generation, feature-level generation, feature-clone 세 가지 방식으로 생성하고 각각의 방식의 결과와 효과를 분석한 결과 depth loss는 오히려 image-level generation 방식에선 성능 저하를 일으켰고, depth estimation model을 사용하는 것이 더 높은 성능을 내는데 도움이 되었고, feature-clone의 경우 generalization capability가 높았습니다.
- image-level generation의 경우 forward warping이 미분이 불가능해 학습이 안 되는 문제를 feature-level generation에선 DDC를 이용해서 미분이 가능하게 만들어 학습을 통해서 더 좋은 feature를 추출할 수 있게 하여 성능을 더 높일 수 있었습니다.
CVPR 2022에 accept된 논문 Pseudo-Stereo를 리뷰해보도록 하겠습니다.
Abstract
Pseudo-LiDAR는 depth-estimation을 더 강화시켜 monocular에서 매우 좋은 성능을 내왔습니다. 또한 강화된 stereo 3D detector도 3D object를 정확히 localize 할 수 있습니다. 이때 stereo view를 위해서 image-to-image를 생성해내는 것이 image-to-LiDAR를 생성하는 것보다 gap이 더 적다고 합니다.
→ image로부터 LiDAR를 생성해내는 것보다 image로 부터 같은 modality를 가지는 image를 만드는 것이 더 효과적이기 때문입니다.
위와 같은 이유로 아래에 적힌 세 가지 참신한 view 생성 방법을 사용하는 Pseudo-Stereo 3D detection framework를 제안합니다.
- image-level generation
- feature-level generation
- feature-clone
depth-aware learning에 대해서 분석을 해본 결과 depth loss는 오직 feature-level virtual view generation에서만 효과적이고 estimated depth map은 image-level, feature-level 모두 효과적이라고 합니다.
→ Method 부분을 읽으면 더 자세히 설명됩니다. (depth loss는 image-level generation의 경우엔 성능을 오히려 저하시키는 요인이 되고 estimated depth map을 사용하는 것이 더 높은 성능을 내는데 도움이 됩니다.)
따라서 disparity feature map에서 샘플링된 dynamic kernel을 사용해 virtual image feature를 생성하기 위해 single image에서 feature를 필터링해주는 disparity-wise dynamic convolution을 제안해서 depth estimation error로 인한 성능 저하를 완화시킵니다.
Pseudo-Stereo는 KITTI-3D의 car, pedestrian, cyclist 모두 1등을 차지했습니다.
Introduction
이전 monocular 3D object detection 논문들에서도 언급하였지만 가장 큰 문제는 single image에서 정확한 3D 정보가 부족하다는 점입니다. 하지만 저렴하고 설치가 간단하기 때문에 높은 potential이 존재하여 연구할 가치가 있습니다.
사전에 학습시킨 depth estimation network를 통하여 pseudo point cloud, pseudo voxel을 생성하여 LiDAR-based 3D detector에 넣어서 3D 물체 검출을 진행하는 Pseudo-LiDAR는 많은 발전을 해왔습니다. 하지만 Pseudo-LiDAR는 image를 LiDAR 형식으로 생성하는 과정에서 생기는 에러로 인해서 그냥 LiDAR 기반의 detector와 성능 차이가 큰 문제가 있습니다.
stereo 3D detector들로도 3D object의 위치를 정확하게 잡아낼 수 있습니다. 또한 stereo view를 위한 image-to-image가 표현 방식을 바꿔야 하는 image-to-LiDAR 보다 gap이 더 작습니다. 따라서 이 논문에서는 monocular 3D detection을 위한 Pseudo-Stereo 3D detection framework를 소개합니다.
이 framework는 single image를 input으로 사용해 하나의 virtual view를 생성합니다. 그 결과로 input으로 받은 single image와 이 image를 이용해 생성해낸 하나의 virtual view, stereo images가 생성됩니다. 그다음 stereo 3D detector(LIGA-Stereo)로 3D detection을 진행합니다.
학습 과정 중 virtual view를 생성하기 위해서 dataset에서의 실제 view ground truth가 필요하지 않다고 합니다. Pseudo-Stereo view를 생성하기 위해서 left view image를 input으로 받고 input으로 virtual right view를 생성하는데 이때 image-level과 feature-level로 생성하는 방법들이 있습니다.
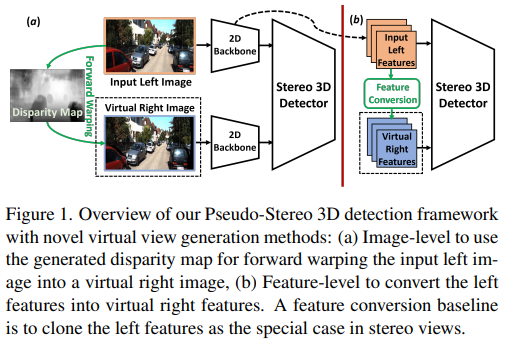
위의 그림이 Pseudo-Stereo의 전체적인 과정입니다. (a) 과정이 input left image로 생성한 image-level의 virtual right image입니다. 과정을 더 설명하자면, input left image로부터 추정한 depth map을 disparity로 변환하고 변환된 disparity를 forward warping을 하여 virtual right image로 사용합니다.
(b) 과정은 left feature를 변환하여 만든 feature level의 virtual right feature입니다. 이 과정에서 disparity feature map에서 샘플링된 dynamic kernel을 사용하는 disparity-wise dynamic convolution을 제안해 depth estimation error로 인한 feature 성능 저하를 완화시켜줍니다.
Pseudo-Stereo의 contribution을 정리하면 아래와 같습니다.
- image-level generation, feature-level generation, feature-clone 이 세 가지 novel view generation 방법을 사용하는 Pseudo-Stereo 3D detection framework를 제시합니다. 이 framework로 KITTI에서 1등을 달성하였습니다.
- estimated depth map과 depth guidance의 역할을 하는 depth loss를 포함하는 depth-aware feature representation learning의 두 가지 주요한 효과를 분석한 결과 depth loss는 feature-level virtual view generation에만 효과적이고 estimated depth map은 image-level과 feature-level 두 가지 모두 효과적이었다고 합니다.
- depth estimation error로 인한 feature 성능 저하를 완화시키기 위해서 disparity feature map에서 샘플링한 dynamic kernel을 사용하는 disparity-wise dynamic convolution을 제안하여 single image로부터 virtual image feature 생성을 위해 feature를 필터링합니다.
Related Work
monocular 3D object detection은 크게 두 가지 group으로 나뉩니다.
- Pseudo-LiDAR based method
→ 사전에 학습된 depth network를 사용하여 pseudo LiDAR representation을 생성하는 방식입니다. - 3D 인지를 위한 추가적인 3D 단서 matching, concatenation, guiding을 통해서 2D feature learning을 사용하는 방법
Monocular 3D Detection.
- GrooMeD-NMS (2021)
2D feature를 추출하여 미분 가능한 NMS로 최고의 3D box candidate를 설정하는 방식입니다. - GS3D (2019)
2D bbox와 3D bbox 사이의 표현의 모호함을 없애기 위해 surface feature를 특별하게 디자인된 2D backbone으로 추출합니다. - MonoEF (2021)
camera extrinsic parameter를 인식하는 모듈을 가지는 2D backbone을 이용해서 3D detection parameter에서 camera extrinsic parameter를 분리하는 방식입니다. - M3D-RPN (2019)
예측한 2D bbox와 3D bbox를 2D로 projection 시킨 두 bbox의 distance error를 최소화하는 방식으로 2D image feature를 추출한 뒤 2D와 3D bbox를 모두 예측하는 방식입니다.
몇몇의 방법들은 2D depth-aware feature를 얻기 위해 depth map으로부터 2D image feature와 depth feature를 추출한 뒤 합치는 방식을 사용합니다.
- D4LCN (2019)
depth-aware feature를 얻기 위해 추정된 depth로부터 학습 가능한 weight와 receptive fields를 가지는 depth-guided convolution을 적용한 방식입니다. - DDMP-3D (2021)
2D depth aware feature를 학습하기 위해 graph를 기반으로 한 depth-conditioned propagation을 사용하는 방식입니다. - DD3D (2021)
3D detection head에 depth prediction head를 추가하고 depth 정보에 예민한 2D feature를 학습하기 위해 depth loss를 사용하는 방식입니다.
또 다른 방식은 2D feature를 추출하고 3D perceiving capacity를 향상하기 위해 2D feature의 변형을 통해 3D feature volume을 생성하는 방식도 존재합니다.
- CaDDN (2021)
추정된 depth 분포를 frustum feature grid로 구성하여 사용합니다. 이때 frustum feature는 known camera calibration parameter를 통하여 voxel grid로 변경하여 3D voxel feature volume을 생성합니다. - ImVoxelNet (2021)
2D image feature를 추출하기 위해서 2D backbone을 사용하고 2D feature를 3D feature volume으로 projection 시킵니다. 그 이후에 3D feature volume을 3D backbone에 통과시켜 3D feature를 강화시켜줍니다.
Pseudo-LiDAR.
Pseudo-LiDAR 구조는 single image로부터 추정된 depth map을 Pseudo 3D data 표현 방식으로 변환시켜 point-wise나 voxel-wise, BEV feature를 학습시키기 위해 3D backbone으로 통과시키는 구조입니다.
- RefinedMPL (2019)
PointRCNN을 사용해 pseudo point cloud로 supervised나 unsupervised 방식의 point-wise feature learning을 진행합니다. - AM3D (2019)
pseudo point cloud로부터 point-wise feature를 추출하기 위해서 PointNet backbone을 사용하고 point-wise feature 학습을 강화하기 위해서 multi-modal fusion block을 사용합니다. - MonoFENet (2019)
추정된 disparity로부터 3D feature를 강화하는 방식입니다. - Decoupled-3D (2020)
추정된 depth map를 변형시켜 만든 BEV feature를 사용하는 3D object height에서 coarse depth를 이용하여 부정확한 depth를 회복시키는 방식입니다.
하지만 Pseudo LiDAR 방식의 성능과 generalization capability는 image와 LiDAR의 data modality의 차이가 큰 image-to-LiDAR 생성의 정확도에 의존적이라는 문제가 있습니다.
Preliminaries of Stereo 3D Detector
Volume-based stereo 3D detector는 stereo image로부터 3D anchor space를 생성하고 3D feature volume으로부터 3D object의 위치를 알아냅니다.
DSGN (2020)은 stereo matching에서 널리 사용되는 3D geometric information encoding을 통해 3D cost volume construction을 진행합니다. 이때 stereo matching branch에서 depth loss는 detection branch의 detection 정확도를 위한 depth-aware feature를 학습하는 것을 돕습니다.
Cost Volume 이란? stereo view를 가지는 두 이미지에 대해서 matching 알고리즘을 적용하여 복수의 영상 중 같은 pixel (x, y) 내 서로 유사 값을 계산하여 cost들을 구해서 3차원의 volume을 생성합니다. 이를 cost volume이라 합니다. 간단하게 말하면 두 stereo view 사이의 강도(intensity)의 차이를 픽셀 단위로 계산해 유사도를 측정한 값들을 pixel 단위로 쌓은 것을 cost volume이라고 합니다.
앞서 언급한 DSGN을 기반으로 한 LIGA-Stereo는 다른 방법들에 비해서 더 많은 개선을 하였기 때문에 Pseudo-Stereo view를 생성한 뒤 LIGA-Stereo에 넣어서 3D detection을 하는 stereo 구조의 base로 사용하였습니다.
따라서 어떻게 input left view를 통해서 virtual right view를 생성할지와 depth 정보에 예민한 Pseudo-Stereo feature를 어떻게 학습할지에 집중을 하여 연구를 진행했다고 합니다.
Stereo Image Feature Extraction.
LIGA-Stereo는 먼저 ResNet-34로 stereo view로부터 left feature $(F'_L)$, right feature $(F'_R)$를 추출합니다. 그다음 최종적인 left feature $(F_L)$ , right feature $(F_R)$ 을 얻기 위해서 spatial pyramid pooling module (SPP)에 추출한 feature를 넣습니다.
The 3D Feature Volume Construction.
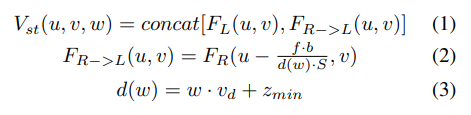
위의 식에 대해서 설명을 하면 (u, v)는 pixel coordinate, $w \in [0,1,\dots]$ 는 depth index, S는 feature map의 stride, $v_d$ 는 depth interval, $z_{min}$ 은 minimal depth value, $f$ 는 camera의 focal length, $b$ 는 stereo camera pair의 baseline을 의미합니다.
$F_L$ 과 모든 후보 depth level의 re-projected right feature $F_{R->L}$ 두 feature를 이어 붙여서 stereo volume $(V_{st})$ 를 생성합니다. ((1) 번 식)
그 이후 stereo network 3D Hourglass를 사용해 stereo volume $V_{st}$ 를 필터링하여 re-sampled stereo volume $(V'{st})$ 와 depth distribution volume $P{st}$ 를 얻습니다.
$P_{st}$ 는 $d(w)$ 로 표현된 모든 후보 depth levels에 대한 픽셀 단위의 depth probability distribution을 나타냅니다.
depth loss는 $V'{st}$ 가 깊이 정보를 학습하는 것을 돕기 위해서 $V'{st}$ 로 regression 된 depth map과 depth map GT 값을 통해서 계산이 됩니다.
Method
1. Pseudo-Stereo 3D Detection Framework
위에서 설명했듯 virtual right image를 통해 stereo-view를 만들어 stereo 3D detector를 통하여 3D detection을 진행합니다. 이때 LIGA-Stereo로 기존의 stereo image의 feature를 추출하는 부분을 이 논문에서 제안한 feature extraction block으로 대체하여 사용하였습니다.
2. Image-level Generation
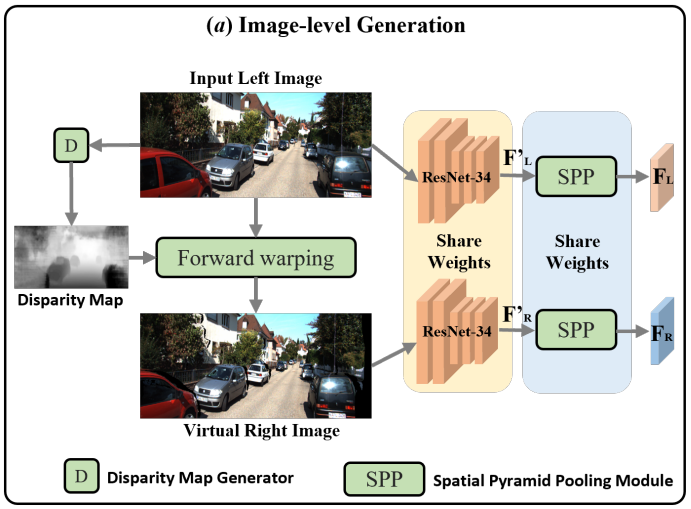
먼저 image-level에서 virtual right image를 생성하는 부분부터 살펴보겠습니다.
사전에 학습된 DORN (monocular depth estimation model)을 사용해서 left image로부터 depth map을 얻습니다. 얻은 depth map을 통해서 forward warping을 이용해 virtual right image를 생성합니다.
이때 사용되는 식은 $d = x_l-x_r...(1), \space d = \frac{f\cdot b}{z}...(2)$ 이 두 가지입니다.
f는 focal length, b는 baseline of stereo camera pair로 camera calibration parameter에 해당합니다. depth map에서 얻은 z로 disparity를 구할 수 있고 이 disparity를 통해서 최종적으로 $x_r$ 을 구할 수 있습니다.

하지만 forward warping을 진행하면 위와 같이 occlussion, collision 현상 때문에 ‘blurry’ edge 현상이 일어납니다. 이를 해결하기 위해서 sharpening과 Sobel edge filter를 사용했다고 합니다.
그 이후에 각각 서로 weight를 공유하는 ResNet, SPP을 통과시켜서 최종적으로 $F_L, \hat{F_L}$ 을 구할 수 있습니다.
3. Feature-level Generation
앞서 설명한 image-level generation의 경우에는 forward warping 때문에 시간이 많이 걸리고 warping 과정이 미분이 불가능하기 때문에 미분이 가능한 feature-level generation 방법을 제안합니다.
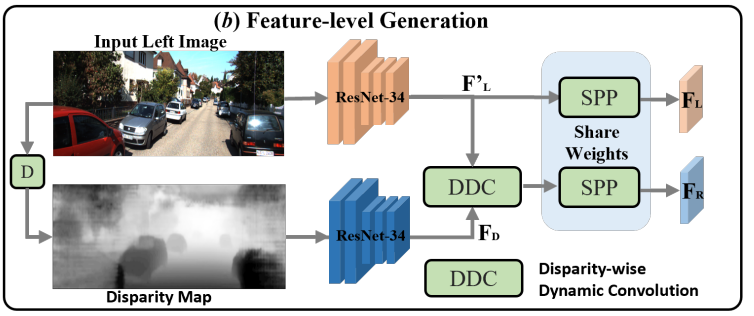
먼저 예측된 depth map을 disparity map으로 변환시켜주고 ResNet-34를 각각 사용해서 left feature map, disparity feature map을 추출해 줍니다. 이때 사용하는 ResNet-34는 각각 weight를 share하지 않습니다.
left image로부터 virtual right image로 옮기기 위해서 offset을 따로 계산해서 보상을 하지 않고 disparity feature map($F_D$)로 부터 동적 커널을 이용해서 left feature map$(F'_L)$ 을 필터 하기 위한 Disparity-wise Dynamic Convolution (DDC)로 virtual right feature map을 생성합니다.
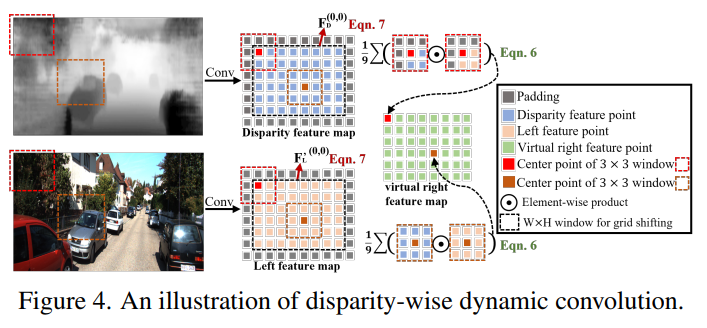
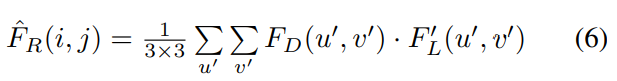
위의 그림과 식이 DDC 과정입니다.
3 x 3 sliding window를 사용하여 $F_D, F'_L$ 의 feature point를 순회하기 위해서 (6)과 같은 수식을 사용합니다. 이렇게 되면 모든 feature map을 순회하는데 W x H 만큼의 sliding 과정을 거쳐야 하는데 이는 매우 비효율 적입니다.
따라서 grid shifting operation을 사용하여 전체 feature map을 9번의 shifting으로 커버할 수 있습니다.
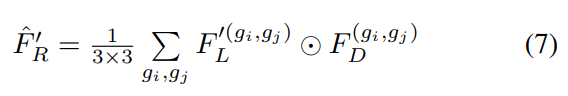
식은 위와 같습니다. $F_D$ 를 dynamic kernel로 사용하여 $F'_L$ 을 필터링하게 됩니다.
4. Image Feature Clone
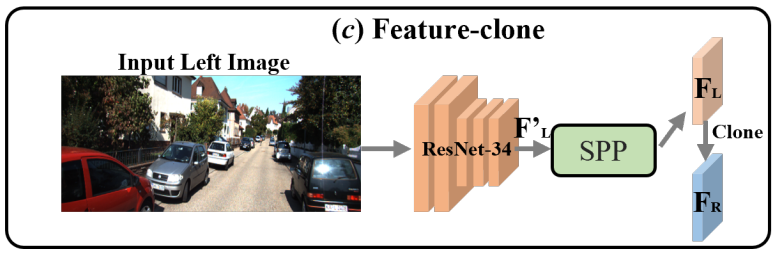
feature clone의 경우는 위 그림과 같이 그냥 input left image를 ResNet-34로 feature를 추출한 $F_L$ 을 clone 하여서 virtual right feature로 사용하는 방식을 말합니다. 서로 다른 pseudo stereo view를 사용한다면 stereo matching에서 사용되는 pixel correspondence constraint나 feature correspondence constraint를 사용하여 3D feature를 개선할 수 있습니다. 하지만 feature clone을 사용한다면 사전 학습된 depth estimation model이 필요 없기 때문에 generalization capability를 높일 수 있어서 사용한다고 합니다.
5. Loss Function
LIGA-Stereo에서 stereo image feature extraction block을 수정하여 사용을 하기 때문에 loss function도 LIGA-Stereo와 같은 function을 사용합니다. 식은 아래와 같습니다.
$L = \lambda_dL_d+\lambda_{dep}L_{depth}+\lambda_{kd}L_{kd}$
식을 설명하자면 $\lambda_d,\lambda_{dep}, \lambda_{kd}$ 는 각각 detection loss, depth loss, knowledge distilation loss를 위한 regularization weight입니다.
6. Learning Depth-aware Features
이 논문의 framework에서 depth feature를 학습하는 부분은 두 곳이 존재합니다.
- The estimated depth map
- The depth loss
위에서 설명했듯 depth estimation model을 이용해 estimated depth map을 생성하고 이를 disparity map으로 전환하여 image space와 feature space에서 사용을 합니다.
depth loss $(L_{depth})$ 는 feature의 depth 정보를 개선시키기 위해 re-sampled stereo volume $(V'_{st})$에 대한 추가적인 guidance로써 사용됩니다.
이제 1번, 2번 방식을 비교해가면서 다시 한번 설명해 보겠습니다.
monocular depth estimation은 고질적으로 ill-posed problem을 가지고 있습니다. 이로 인해 virtual right image를 생성하기 위하여 좋은 quaility의 depth map을 얻는 것이 어렵습니다.
error가 존재하는 depth map으로 생성한 Pseudo-Stereo view로 pixel-correspondence constraints를 사용하게 되면 GT와 큰 차이를 가지게 될 것입니다. 이는 feature의 성능 저하로 이어지게 되고 GT depth와 성능 저하된 feature 사이에 매우 큰 gap이 생깁니다. 이는 network가 depth loss를 통해서 성능 저하된 feature와 GT depth map을 fit 하게 강제하면 전체적인 성능 저하가 일어나게 됩니다.
하지만 forward-warping은 학습이 가능하지 않은 (미분이 불가능한) 과정인 image-level generation와 달리, feature-level generation은 DDC (disparity-wise dynamic convolutions)을 통하여 학습 과정을 통하여 진행됩니다.
또한 예측된 depth 정보는 높은 차원의 feature space로 임베딩 되고 그 임베딩 된 depth 정보는 feature-level generation에서 left feature를 필터링하는 데 사용이 됩니다.
이는 depth 정보의 성능 저하를 줄여주고 GT와 feature 사이의 gap을 완화시켜줍니다.
Experiments
KITTI 3D object detection benchmark를 이용해서 모델을 평가하였습니다.
실험에 대한 input setting에 대한 설명을 하겠습니다.
- 사전 학습된 DORN (depth estimation model)을 사용하여 input left image로 depth map을 생성합니다.
- 만들어진 depth map을 camera calibration parameter를 사용하여 disparity map으로 변환해 줍니다.
- 학습 시간을 줄이기 위해서 학습하기 이전에 image-level generation으로 virtual right image를 생성해 둡니다.
- feature-level generation을 위해서 disparity map을 $\mu=33.20, \sigma=15.91$ 을 사용하여 normalize를 진행합니다. 이때 $\mu, \sigma$ 는 각각 disparity map의 mean, variance를 의미합니다.
Ablation Study
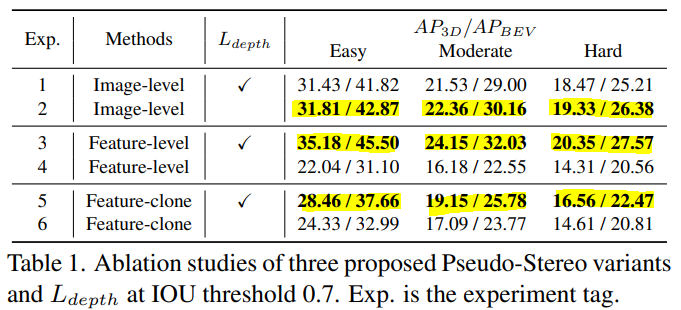
앞서 설명했듯이 image-level에서 depth loss를 사용하는 것은 estimation depth map에 존재하는 error로 인해서 오히려 성능이 저하되는 것을 볼 수 있습니다. 따라서 Image-level generation을 사용한 경우엔 depth loss를 사용하지 않는 것이 더 높은 성능을 보입니다. 반대로 feature-level generation과 feature-clone의 경우엔 depth loss를 사용하는 것이 더 좋은 성능을 보입니다.
feature-clone과 image-level, feature-level을 각각 비교해보면 depth estimation model을 사용하는 것이 성능 향상에 큰 도움이 되는 것을 볼 수 있습니다.
또한 DDC를 사용한 경우에도 큰 성능 향상을 볼 수 있습니다.
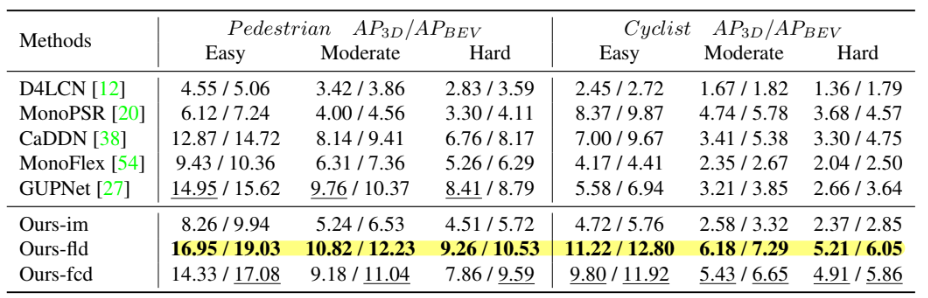
위 표의 method는 Ours-im는 image-level generation without depth loss, Ours-fld는 feature-level generation with depth loss, Ours-fcd는 feature-clone with depth loss입니다.
결과적으로 feature-level generation with depth loss가 가장 높은 성능을 냈습니다.
이전에 위에 table 1의 경우엔 KITTI val set에서 평가한 점수이고 바로 위의 table은 KITTI test set에서 평가한 점수입니다. 모두 test set의 경우 val set보다 성능이 떨어졌습니다. 이는 overfitting의 영향입니다. 하지만 feature-clone의 경우엔 estimated depth map을 학습 과정 중 사용하지 않으므로 더 나은 generalization capability를 가져서 성능 차이가 크게 나지 않았다고 합니다.